ARTICLE
From Blind Spots to Merged PRs: Why Your Coding Agents Need Runtime Intelligence
Discover why coding agents need runtime intelligence to avoid costly PR mistakes. Learn how to bridge the gap between code and real-world performance.

May Walter
When Innocent-Looking PRs Hide Grave Production Costs
Last week I reviewed a pull request written by a coding agent. The change was clean, the tests passed, and the PR description explained the refactor in perfect prose. But, the function it touched runs 40,000 times a minute in production, and the "optimization" was about to add two extra DB calls to every execution.
The agent wrote a reasonable change for the code it could see. The problem was what it couldn't see: how the function actually behaves in reality under real traffic. This is the gap I've been stuck on, and it's the one I'll be talking about at The Tool Call on June 1st.
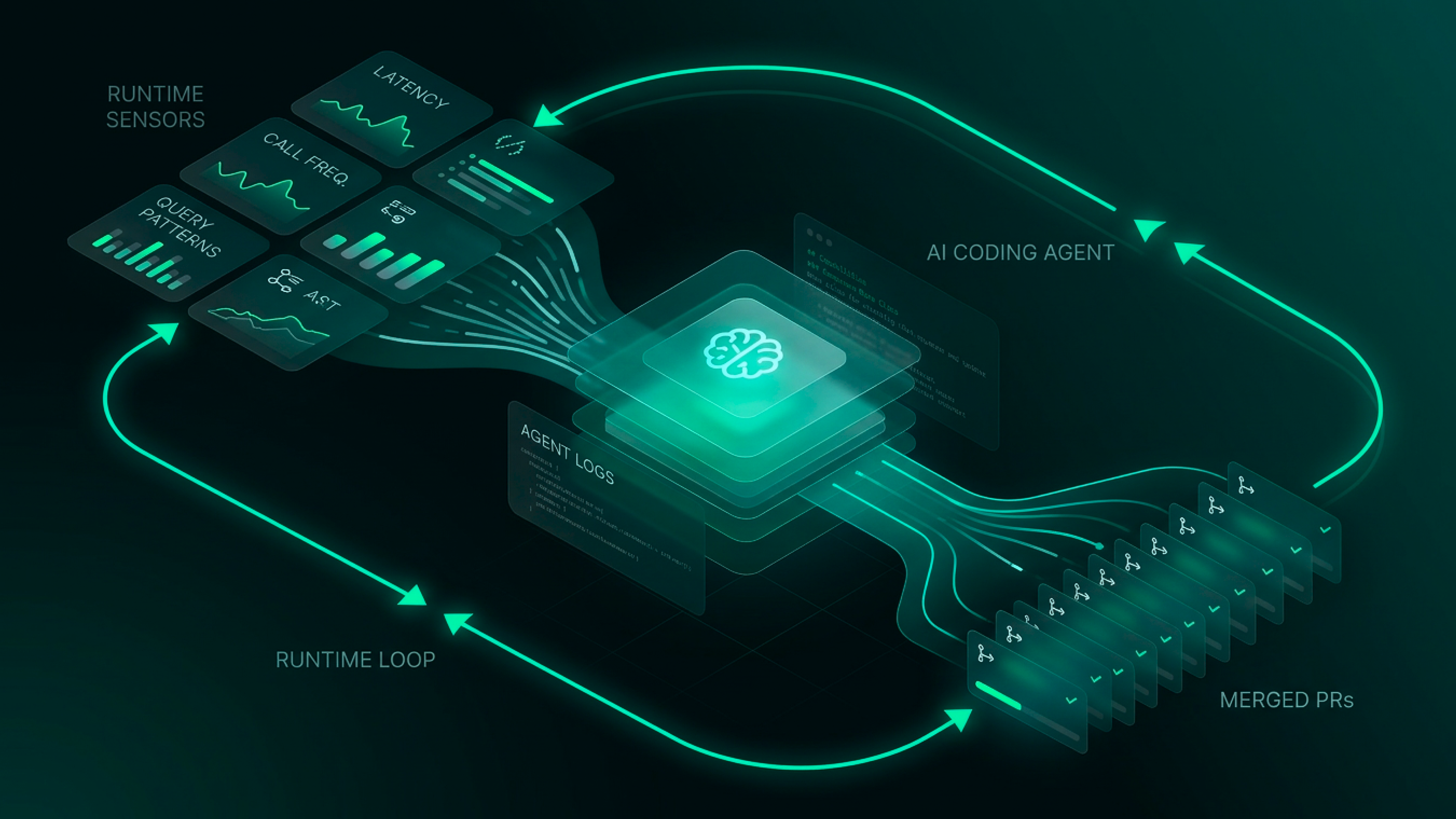
The Need for Runtime Intelligence
Hi, I'm May, co-founder and CTO at Hud. We build runtime sensors for AI agents, the kind of bridge between what an agent writes and what actually happens when that code runs at scale. Before this, I spent years in runtime internals and cybersecurity, which is a fancy way of saying I got comfortable hanging in production for a living.
In the last 18 months agents went from "autocomplete on steroids" to shipping real PRs, which is awesome. But the loop we set them up with (lint, typecheck, unit tests, human review) was designed for humans who were already grounded in how the system behaves. Agents aren't grounded in the reality of the system. They're brilliant pattern-matchers working from static code, a prompt, and maybe a linter.
The result is a specific failure mode I see over and over: agents optimize the wrong thing, refactor hot paths without knowing they're hot, or "clean up" code that was load-bearing for a reason nobody wrote down. Many teams respond by adding more review, relying even more on the senior engineers with most institutional knowledge. I don't think that scales. I think the solution is giving the agent the context a senior engineer would have before touching the code: what runs 60k times a minute, what runs once a day, what relies on a flaky dependency, and what's been quietly rotting in production for six months.
3 Things I’ve Been Wrong About
Three things I've been wrong about, or at least underweighted, along the way.
1. "Better prompts" aren’t enough to close the gap
The conventional wisdom is that as models get smarter and context windows get longer, agents will naturally figure out performance. But I don’t think it’ll be that easy. A long context window doesn't tell you which query runs inside a loop, which index is missing, under what conditions a function has rare performance spikes, or which function is slow because of a cold cache on Tuesdays. Those facts don't live in the repo. They live in production.
The solution sounds boring and unglamorous: feed the agent real signals from runtime. At Hud, we developed a runtime layer that allows us to hand the agent a compact view of what matters per function: call distribution, latency under different conditions, query patterns, error rates. All indexed by function, for every function. Not heaps of logs and traces that the agent struggles to correlate, but an explicit function-level dataset.
For example, with one of our customers on the day we enabled Hud, the agent found and opened PRs for two N+1 queries and a missing composite index. There was prior awareness of these issues, but nobody had gotten to fix them - because they were difficult to prioritize. But once the data showed it was impacting a multitude of customers and the solution was low risk, the team solved the problem with runtime context. P90 latency dropped measurably after the deploy - just by adding the right context.
2. "Performance work" is the wrong framing
Conventional wisdom says performance is a sprint, something you schedule when things are "bad enough." But everyone building at scale knows that performance debt accumulates one PR at a time, mostly invisibly, and you never get permission to stop and fix it. Every tech lead I talk to recognizes this, and every tech lead has the same frustrated answer: I wish we could spend more time on reliability, but we have to ship features.
What we should do instead is stop treating performance as a project and start treating it as a background process. If the agent has runtime context, it can open small, boring, high-impact & low risk PRs in the margins of the week, ranked by real impact rather than by whoever complained loudest. The tech lead's job shifts from "find the problem" to "approve the fix." That's a much better use of a senior engineer's attention, and it arrives before sprint planning rather than after the incident.
3. The interesting work is in the feedback loop, not the code
I used to think the hard part was getting the agent to write good code. After shipping this, I think the hard part is closing the loop: the code ships, runtime changes, and the now you want the agent's next suggestion to reflect that change. Without that, you get a one-shot optimizer that burns out after the easy wins.
Concretely: the runtime sensors automatically pick up the new latency profile after every new deployment, the prioritization shifts, and the next candidate fix is usually something we wouldn't have looked at - now based on actual real world behavior of the new code. That compounding is where the value is. The first PR is a demo, but by the 10th PR you’ve got yourself a system.
TL;DR
Coding agents don't fail because models are weak. They fail because they're working without the context a senior engineer takes for granted, the one that lives in production, not the repo. Close that loop and a lot of "hard" performance work turns into a steady drip of merged PRs.
If you're coming to The Tool Call on June 1st, I'll walk through the full case study, including the parts that didn't work. If you're not, come find me after. The thing I'll try to prove is that the next order of magnitude in agentic engineering isn't a better model. It's a better view of production.
COPY & SHARE
May Walter
May Walter is an engineer, researcher, entrepreneur and serial CTO. She is the Co-Founder and CTO of Hud, building a Runtime Code Sensor to bridge the gap between coding agents and production in the AI era. Before Hud she was a founding CTO at Santa, and CTO at Bond (acquired by REEF Technology). May is a renowned runtime internals and adversarial red-team cybersecurity expert, a leadership mentor, and frequently speaks about the topics at the intersection of deep technology and engineering culture.
READING
·
0%
IN THIS POST
COPY & SHARE
May Walter
May Walter is an engineer, researcher, entrepreneur and serial CTO. She is the Co-Founder and CTO of Hud, building a Runtime Code Sensor to bridge the gap between coding agents and production in the AI era. Before Hud she was a founding CTO at Santa, and CTO at Bond (acquired by REEF Technology). May is a renowned runtime internals and adversarial red-team cybersecurity expert, a leadership mentor, and frequently speaks about the topics at the intersection of deep technology and engineering culture.