17 Feb 20265 minute read


Introducing Task Evals: Measure Whether Your Skills Actually Work
17 Feb 20265 minute read
You've encoded your team's conventions into skills: coding standards, review checklists, deployment patterns. The agent seems to follow them. But how do you know?
Models update, prompts evolve, teammates add context, and the failure mode is silent: the agent quietly drifts from your conventions and nobody notices until it shows up in review or production.
Today we're shipping task evals, a built-in way to measure whether a skill is genuinely steering agent behaviour, and to catch when it stops.
Why now
Skills are no longer a handful of files maintained by one person. They're multiplying across teams, shared through registries, and applied to codebases their authors have never seen. The context that steers your agents is becoming a distributed system of its own, and it needs the same quality signals you'd expect from any other shared dependency.
Tessl already checks how well your skill is written: whether it follows best practices for structure, clarity, and description. Those checks tell you if the skill is well constructed. Task evals ask the next question: is it actually effective? Does it change what the agent does when it matters?
How it works
When you run an eval, Tessl generates realistic scenarios by analysing the skill and its related files. It triages which scenarios can actually be tested, discarding any that can't produce a meaningful eval. Then it runs two comparisons:
Baseline: the agent attempts each task without your skill.
With skill: the agent attempts the same task with your skill.
Outputs are scored against a set of criteria that Tessl also generates for you, so you don't have to figure out what to test. What matters most is the gap between the two scores.
If the agent does much better with your skill than without, the skill is doing its job. If there's barely any difference, the agent was already doing this on its own. And if the agent actually does worse with the skill, that's a signal the instructions might be confusing or contradictory.
See it in action
You can evaluate your own skills by following this guide. Tessl analyses the skill, generates scenarios and scoring criteria, then runs the agent through each scenario twice: once without the skill, once with it.
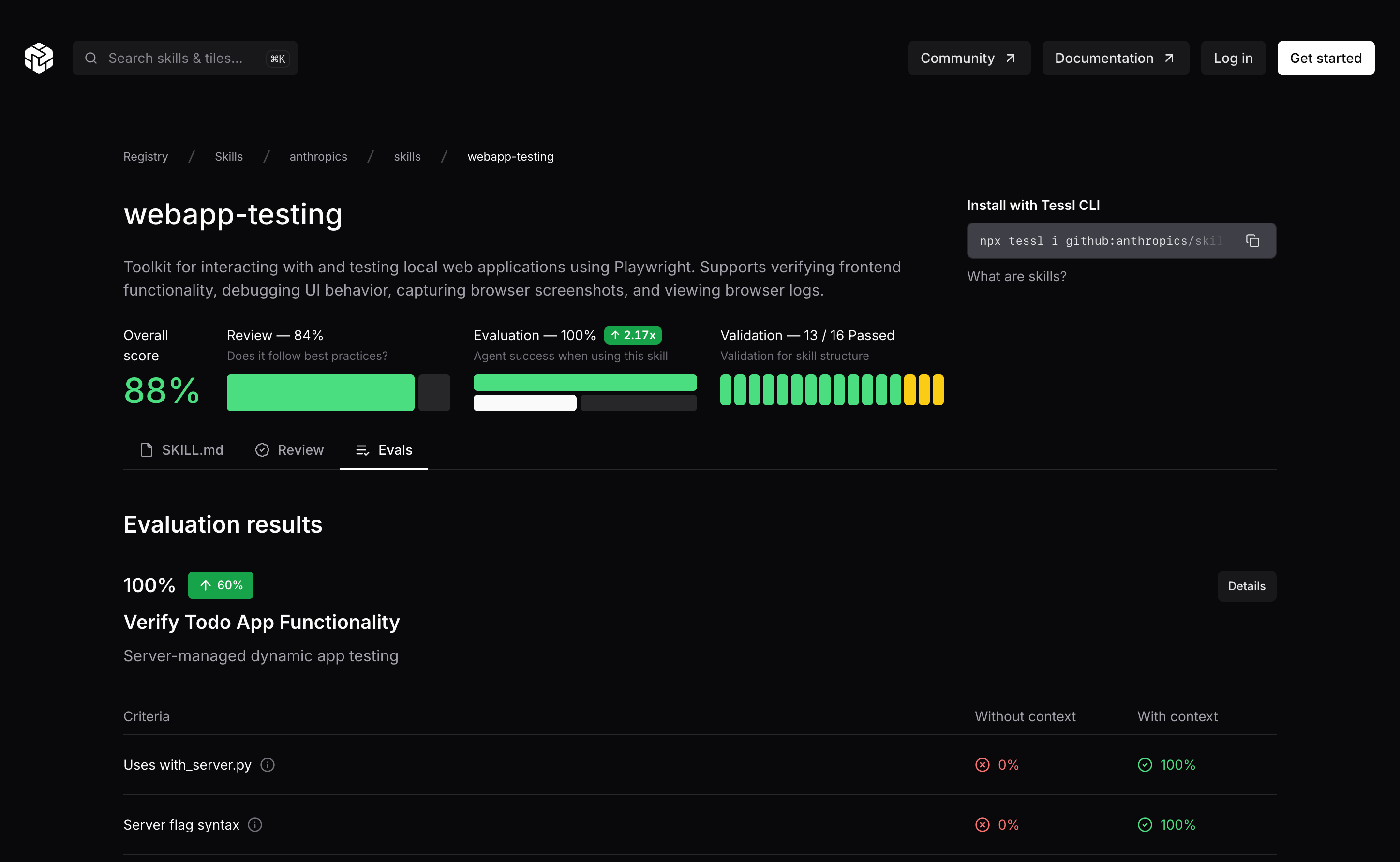
https://tessl.io/registry/skills/github/anthropics/skills/webapp-testing/evals
The results show you a baseline score (how well the agent already does what the skill asks, even without it) and a with-skill score. The difference tells you how much steer your skill actually provides. For example, if the baseline is low and the with-skill score is high, your skill is teaching the agent something it wouldn't do on its own. If both are high, the agent was already doing this and the skill may not be adding much value.
You can explore eval results from published skills on the Tessl registry to see what this looks like in practice — for example, Anthropic's webapp-testing skill.
Iterate on skills like code
Task evals give you a tight feedback loop for skill development. Without them, refining a skill means changing it, manually trying a few tasks, and hoping it generalises. With evals, the loop becomes: write skill → run evals → inspect where the scores are weak → refine → repeat.
Task evals make skills testable, so you can iterate with confidence instead of guesswork.
Skills are key to help agents use the rapid new ElevenLabs feature stream. Tessl's evals help us ensure our skills work well, so we can keep delivering a top tier developer experience to agentic devs.
Luke, Head of Growth at ElevenLabs
We have tens of thousands of engineers using AI tools daily who need support to shift from prompting to context engineering. I believe Tessl's approach to measure, package, and distribute that context automatically is the solution that can unlock agent productivity.
John Groetzinger, Principal Engineer at Cisco
What's next: Repo evals
Task evals measure whether a skill changes agent behaviour in general. But how well does it perform in your codebase? That's what repo evals will answer — testing the combination of your skill, the agent, and your actual repository to measure real-world effectiveness where it matters most.
Repo evals are currently in beta. Leave your email to get notified when they launch.
Get started
Task evals are available now. Run evals against your own skills or explore evaluation results from public skills in the Tessl registry.
Run your first eval → Follow the Task Evals quickstart.


