12 Nov 202519 minute read





A Proposed Evaluation Framework for Coding Agents: Tiles Enhance Proper Use of Public APIs by ~35%
12 Nov 202519 minute read
LLMs generate code quickly but often miss the conventions and idioms that make real software reusable. Using a dataset of tasks based on real software libraries, we find that coding agents frequently fail to follow idiomatic library usage.
To address this gap, Tessl built the Tiles Registry, (https://tessl.io/registry), which includes versioned documentation for 10,000+ libraries, as well as private and custom specifications, that offer agents precise, contextual API guidance.
Tessl’s documentation improves agents’s abstraction adherence by 50%
on new libraries, and 35%
overall, while reducing runtime and interaction turns. A LangGraph case study reveals up to 90%
improvement on newly added features when using Tessl’s tiles of documentation.
For developers, this means that tiles help agents produce more accurate, reusable code with less back-and-forth.
Why coding agents misuse public APIs and how specs fix it
Modern software engineering is built on reuse. While coding agents can rapidly create code from scratch, effective reuse saves compute and reduces the surface for implementation errors.
However, software interfaces require precise invocation and are constantly evolving with new versions. This is creating an inherent mismatch for LLMs pre-trained on data that is static, inconsistent, and unevenly distributed. As a result, coding agents introduce incompatible dependencies, invent APIs, use them in non-idiomatic ways, and reimplement existing abstractions. This leads to low-quality, inefficient, and often broken code that is difficult to reuse.
To better illustrate the point, imagine for a second that a cutting-edge LLM was pre-trained on PyTorch before version 2.x was released. If a user were to ask it to “Add efficient scaled dot-product attention with masking to a Transformer block,” the model might produce a naive implementation like this:
import torch
import torch.nn.functional as F
def bad_attention(q, k, v, attn_mask=None, dropout_p=0.0):
# q, k, v: (batch, heads, seq, dim)
# Manual matmul + softmax + dropout, with Python control flow
scale = q.size(-1) ** -0.5
scores = torch.matmul(q, k.transpose(-2, -1)) * scale
if attn_mask is not None:
scores = scores.masked_fill(attn_mask == 0, float("-inf"))
probs = F.softmax(scores, dim=-1)
if dropout_p > 0:
probs = F.dropout(probs, p=dropout_p, training=True)
return torch.matmul(probs, v)
However, PyTorch 2.x provides a native, optimized one-liner implementation:
import torch
import torch.nn.functional as F
def good_attention(q, k, v, attn_mask=None, dropout_p=0.0, is_causal=False):
# q, k, v: (batch, heads, seq, dim)
# Uses optimized fused attention available in PyTorch 2.x
return F.scaled_dot_product_attention(
q, k, v,
attn_mask=attn_mask,
dropout_p=dropout_p,
is_causal=is_causal,
)This example is illustrative but imagine a niche library or emerging framework that were never part of the LLM’s pre-training dataset. In that case, the model simply never had a chance to learn how to use it correctly.
To better understand the scale of this problem, we built an evaluation framework and collected a dataset of coding tasks from various open-source libraries. We measured both the correctness of generated code and its adherence to the framework’s idiomatic usage. Our evaluation showed that standalone agents, such as Claude Code or Cursor, achieve only about 60% accuracy in these tasks.
To address this gap, Tessl launched the Tile Registry, which contains tiles for 10,000+ open-source libraries. Tiles contain documentation for coding agents that provide the contextual knowledge needed to use the specified software. Tiles are versioned alongside the software they describe, and Tessl embeds the documentation directly into user environment, so agents can work with the user’s precise software stack as it evolves.
Our primary results show that pairing tiles with a coding agent such as Claude Code and Cursor yields approximately an 35% overall relative improvement in the abstraction adherence evaluation compared to the baseline. For recently released libraries, the relative improvement is 50% on average, while a case study using LangGraph reveals up to 90% relative improvement on newly added library features. The agent also requires less runtime and fewer total turns to complete tasks compared to the version with direct access to source code. This combination of higher performance and greater efficiency makes our approach well-suited for producing high-quality, idiomatic code.
Let’s dive deeper into our approach.
Experimental Setup: Terminal Bench Environment and Claude Code
To evaluate the practical value of Tessl's tiles, we created a dataset of questions that probe knowledge of public APIs from real-world packages, each paired with specific evaluation criteria. We then solved these questions both with and without tiles and assessed the solutions according to the pre-generated criteria. We explain each step in detail below. The diagram summarizes our experimental pipeline.
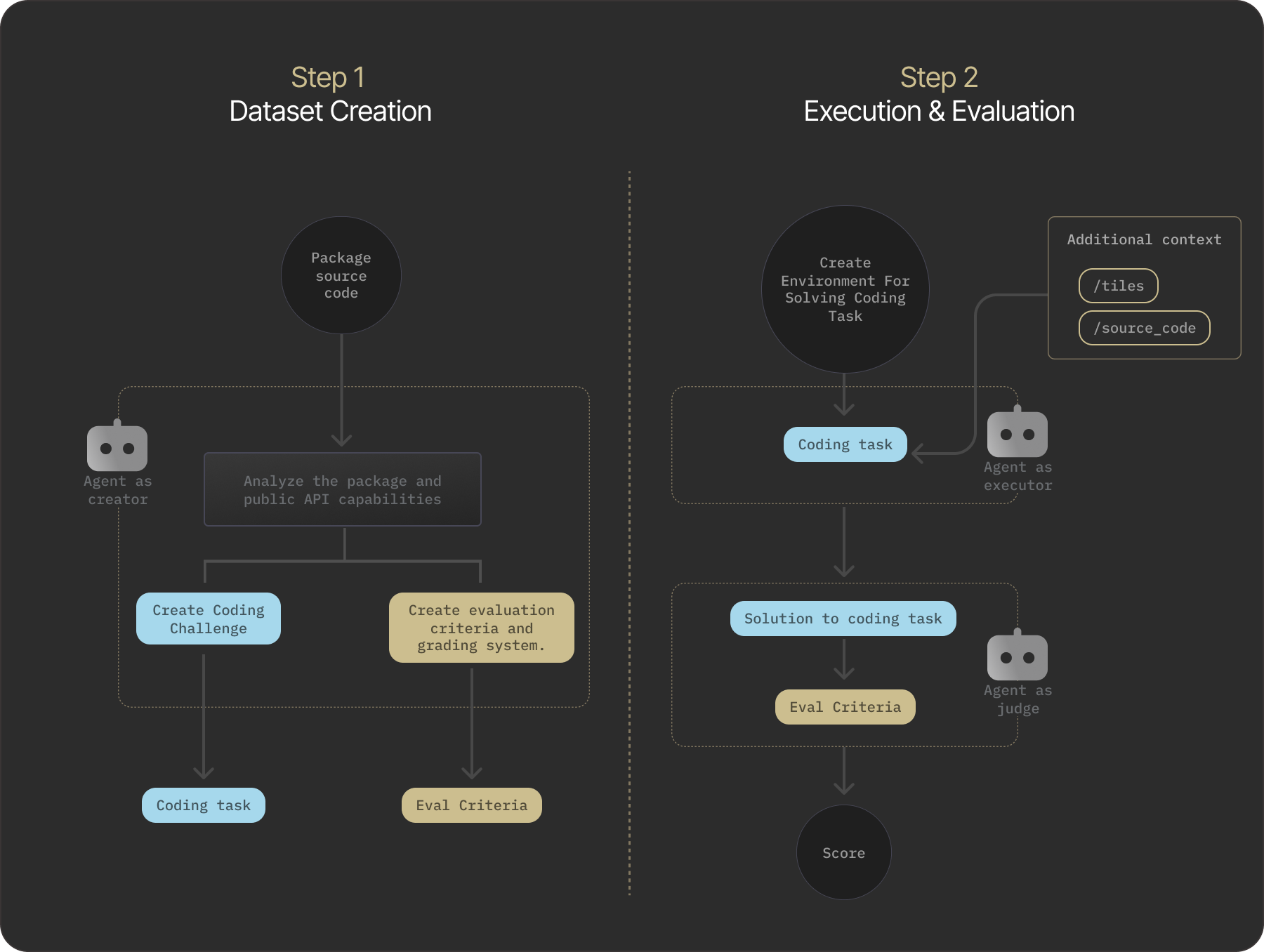
Dataset
We cloned ~270 popular JavaScript (npm) and Python (pypi) repositories, including well-known core libraries and newer or more niche libraries.
For each repo, we launched a Claude Code instance to explore the repo’s source and construct a coding task that requires a nuanced understanding of the repo’s public API. Each task included a natural-language problem description and a declaration of method signatures to be implemented.
We then asked Claude Code to produce a points-based evaluation rubric similar to the approaches used here and here. Each rubric is task- and repo-specific, capturing objective (e.g. correctness, API usage) scores for how well a solution utilizes the repo.
The full list of repos, questions, and corresponding criteria for each question is provided in the Appendix.
An example coding task and a corresponding criteria are presented below:
# Custom Animation Timeline
Build an animation timeline system to coordinate multiple animations with precise timing, supporting springs, tweens, and sequencing.
## Spring Animation
- A spring with initial value 0 and setting target to 100 results in animated transition toward 100 [@test](test/spring-basic.test.js)
- A spring with stiffness 0.5 and damping 0.9 produces critically damped motion with minimal oscillation [@test](test/spring-physics.test.js)
.... more specifications ..."checklist": [{
"name": "Spring class usage",
"description": "Uses the Spring class from svelte/motion to create animations. Instantiates with new Spring(value, options) and configures stiffness, damping, and precision.",
"max_score": 20
},{
"name": "Spring.set() method",
"description": "Uses Spring.set(value, options) ...",
"max_score": 15
},{
"name": "Spring reactive properties",
... more rubrics ...Agent Setup
We evaluate three configurations of the Claude Code and Cursor agent with the Sonnet 4.5 LLM as its backend:
- Baseline. Claude Code or Cursor, with access to all built-in tools (including web search), is asked to solve the problem.
- Agent with access to source code. Claude Code or Cursor is given the source code of the repo corresponding to the task and explicitly directed to reference it while solving the problem.
- Agent with access to tiles. Claude Code or Cursor is given access to Tessl’s tiles for the repo and explicitly directed to reference them while solving the problem.
One could argue that the baseline approach and the version with source code access are no different, since the agent could, in theory, inspect the source code already installed as a dependency. However, without explicit guidance, the agent isn’t incentivized to do so or to thoroughly explore the package before generating code. In contrast, providing explicit access and instructions to use the source code gives us a good understanding of the upper bound of performance.
Evaluation Approach
We use the Terminal Bench framework (source) to construct harness environments for solving and grading tasks in stages. Each task is run three times per setup, with scores averaged to obtain a final score per setup.
- Solution environment.
- We launch a Docker container with the task description and any additional input depending on the method being evaluated (baseline, source code, or tiles).
- The container includes all dependencies required to solve the task, preinstalled and available system-wide.
- Claude Code (or Cursor) solves the problem, with access to all built-in tools and permission to run its code, generate tests, and run self-fix loops.
- The agent has 30 minutes to solve the task, working in the
/appdirectory.
- Grading environment.
- We launch a separate container with the
/appdirectory and the criteria file for grading. - A new instance of Claude Code with Sonnet 4.5 judges the solution against the criteria.
- We launch a separate container with the
Validation
To validate our methodology, we assess solutions generated with Claude Code using various models of known, varying capability: Haiku 3.5, Haiku 4.5, Sonnet 3.7, Sonnet 4.0, and Sonnet 4.5. As expected, our evaluation approach correctly sorts the solutions according to model strength as shown below.
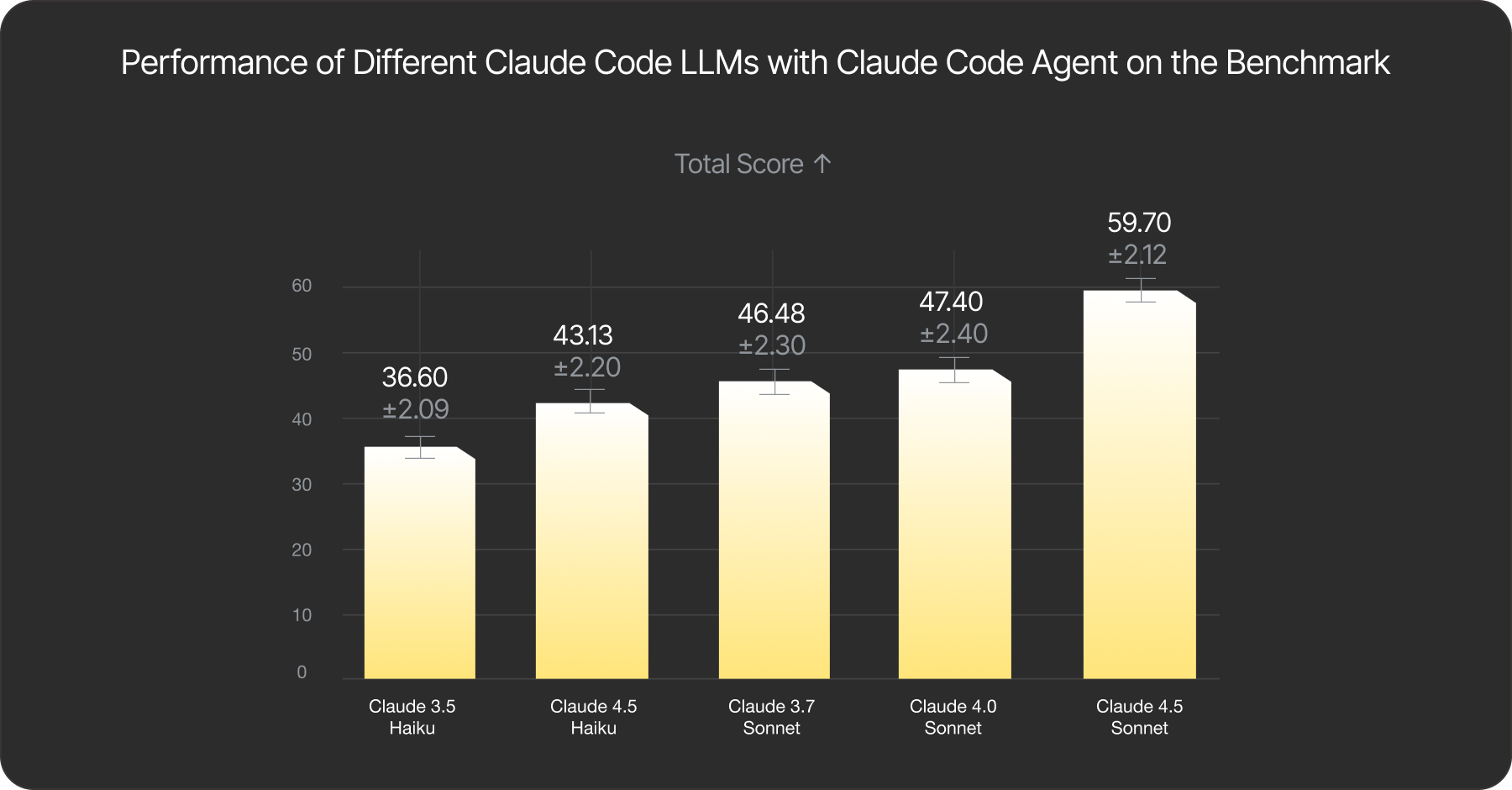
Fig. 1: Performance of different models in Anthropic’s family on the benchmark. Larger and more recent models achieve higher scores. A higher score indicates better abstraction adherence.
Results: Tiles make coding agents 35% more accurate when using open-source libraries
We conduct three experiments using Claude Code agent on the dataset described above and summarize the findings in the figure below. In addition to the score generated by our evaluation rubrics, we also track the time (in minutes) taken to complete the task and the total number of agent turns required.
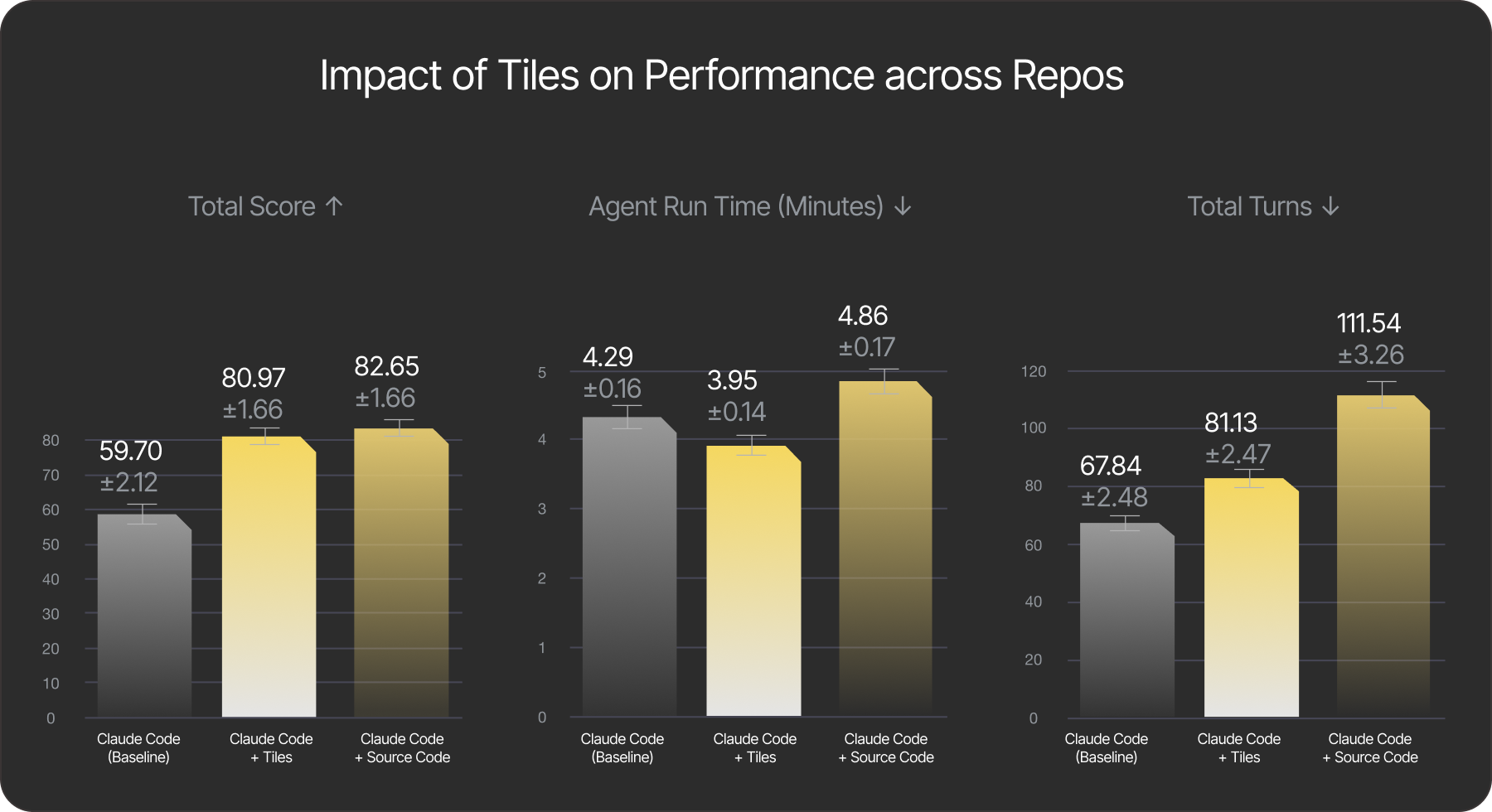
Fig. 2 - Key results of the work. All experiments use Claude Code agent with Sonnet 4.5 LLM. Plot 1 (higher is better): The agent with tiles significantly outperforms the baseline in accuracy while performing on par with the agent that has direct access to the source code. Plot 2 (lower is better): The agent with tiles solves the challenge faster, or on par with the baseline, while outperforming the agent with source-code access. Plot 3 (lower is better): Number of turns taken by the agent.
Tiles deliver meaningfully higher quality than Baseline overall, and do so faster than both the Baseline and the Source Code setups. On average, tiles deliver a relative improvement of approximately 35% over the Baseline. The gap is larger for pypi packages at ~40%:
| Package Type Baseline | Baseline | Tiles | Source Code |
|---|---|---|---|
| npm (161) | 60.86 | 81.01 | 80.67 |
| pypi (106) | 57.94 | 80.9 | 85.66 |
| all | 59.70 | 80.97 | 82.65 |
The Source Code setup delivers quality comparable to the Tiles setup. However, it incurs both higher costs and noticeably longer execution time. We observe that it is 20% slower than the tiles approach.
We are yet to fully explore the cost implications of tiles or source code to improve code generation. Initial results show that achieving a higher abstraction adherence score requires roughly ~$0.006 of additional cost per 1% increase in score for tiles and roughly ~$0.01 of additional cost per 1% increase in score for Source Code. However, we hypothesize that as problem size grows, the marginal benefit of tiles will become more pronounced, for example, due to caching benefits, reduced retries, and amortized effects over multiple calls. We plan to explore such larger problems in future studies.
Additionally, we conducted similar experiments with the Cursor agent. We observed similar patterns across total score, run time, and total number of turns as with the Claude Code agent: access to tiles significantly improves performance across all fronts. The figure below summarizes our findings.
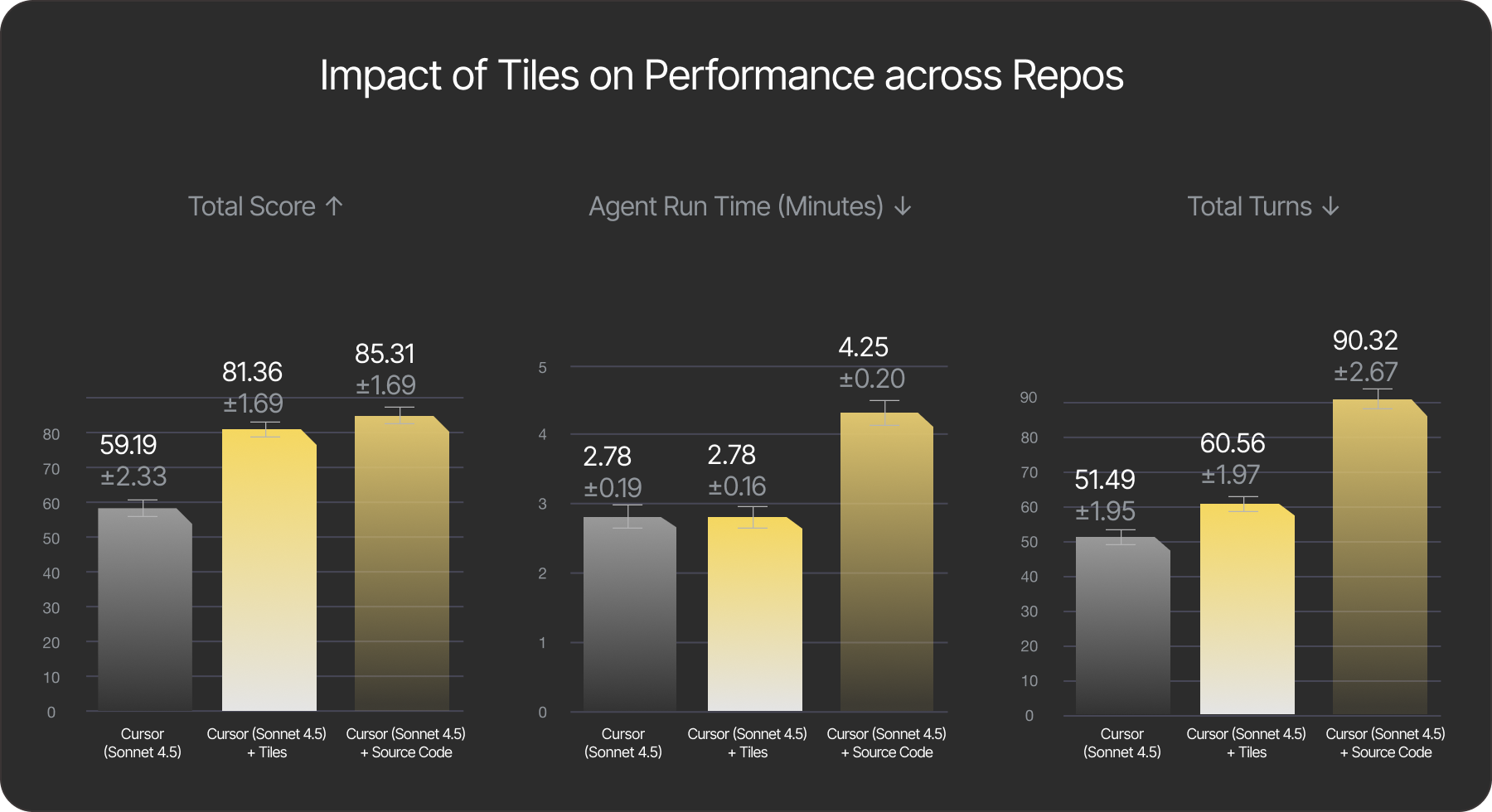
Fig. 3 Key results of the work. All experiments use Cursor agent with Sonnet 4.5 LLM. Left plot (higher is better): The agent with tiles significantly outperforms the baseline in accuracy while performing on par with the agent that has direct access to the source code. Middle plot (lower is better): The agent with tiles solves the challenge faster, or on par with the baseline, while outperforming the agent with source-code access. Right plot (lower is better): Number of turns taken by the agent.
Tiles deliver consistent gains across both niche and popular repos
We were keen to dive deeper and understand how these scores change based on properties of the packages, such as the age and popularity. We analyzed the performance of each method against the year of first release and the number of GitHub forks for each package.
Release year. The baseline model shows a marked decline for older repositories (released between 2005–2011) and for newer ones (released between 2022–2025). This suggests that LLMs struggle both with legacy codebases and with newly emerging packages. In contrast, models using tiles handled legacy code and emerging frameworks more effectively, showing relatively stable performance across the years of first release. Notably, for recently released packages (2022—2025), tiles provided a 50% boost to the abstraction adherence score relative to the baseline.
GitHub Popularity. We measure a weak but statistically significant positive correlation (Spearman ρ = 0.16, p = 0.02) between the abstraction adherence score and the number of GitHub forks. This suggests that Claude Code exhibits a negative bias when it comes to the usage of niche or less popular packages. Conversely, models using tiles maintain broadly consistent performance across repositories, regardless of their popularity (as measured by fork counts).
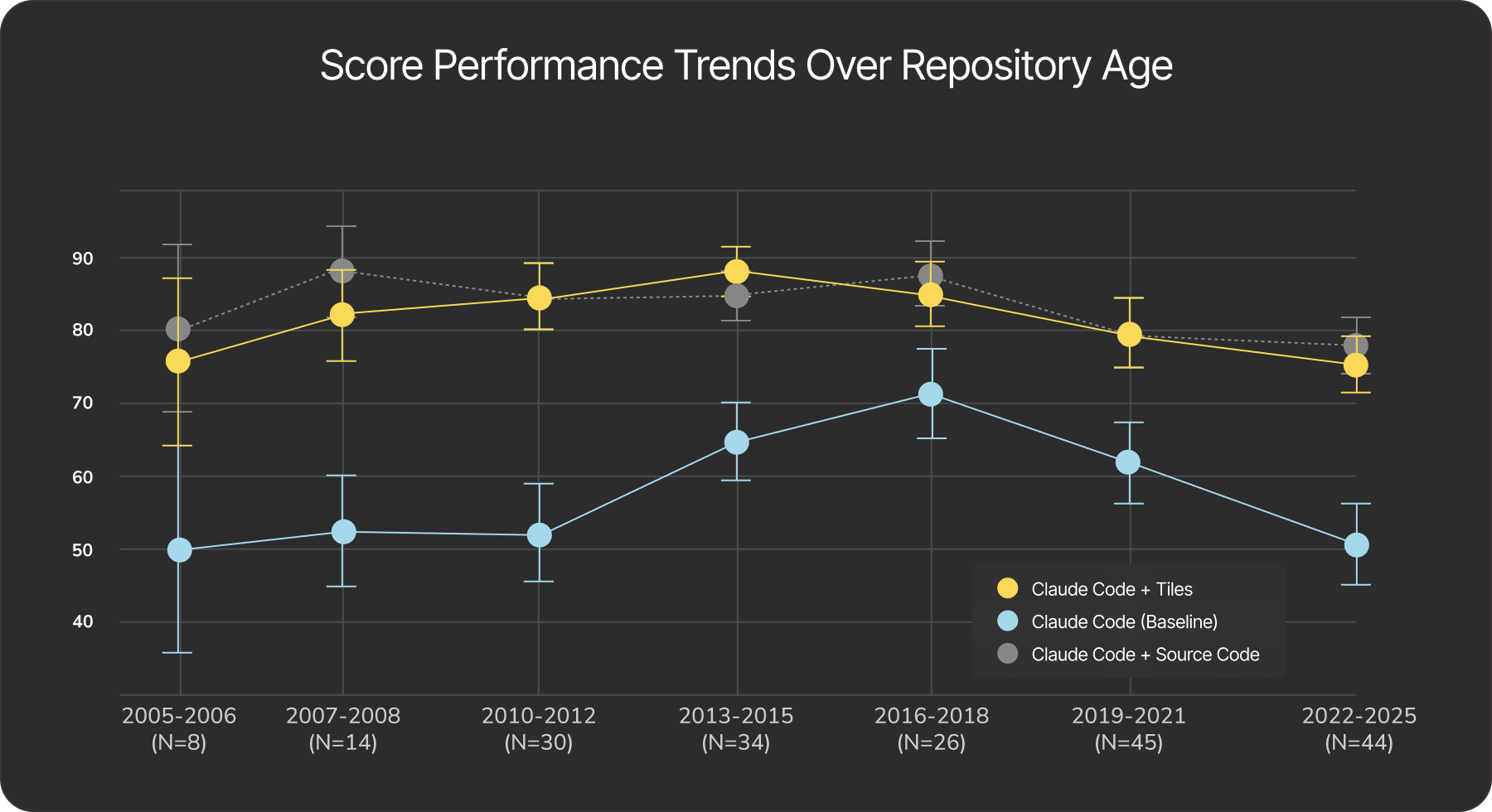
Fig. 4. Performance of the agents across GitHub repositories of different ages. The baseline’s performance drops significantly for older packages (released between 2005–2012) as well as for newer codebases (released between 2021–2025), while the agent with tiles remains stable.
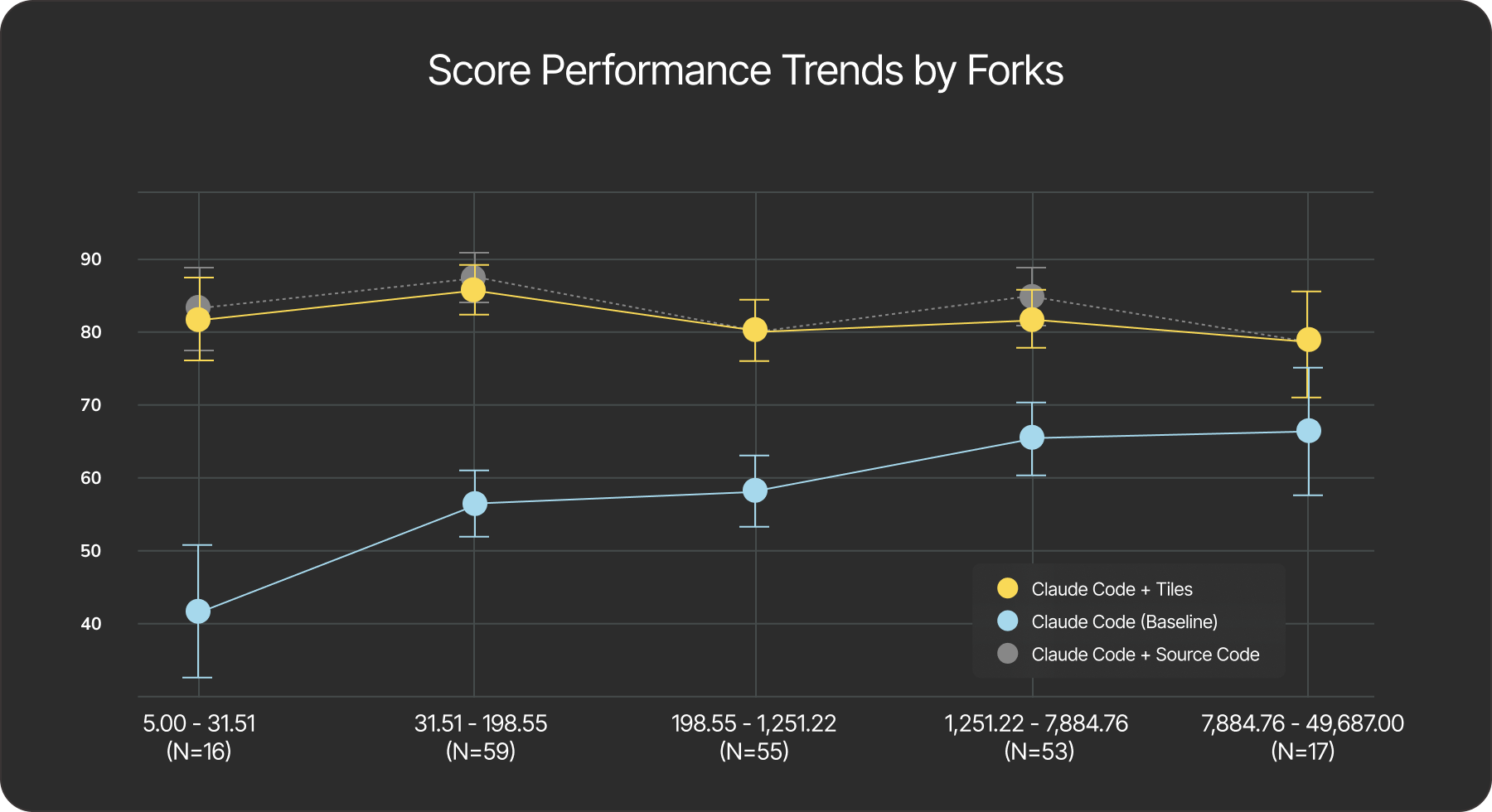
Fig. 5. Performance of the agents across GitHub repositories of varying popularity. The baseline’s performance drops significantly for niche libraries, while the agent with tiles maintains stable performance across all popularity buckets.
Case study: coding agents struggle with new LangGraph features, but tiles close the gap.
To further understand our findings, we conduct a detailed, manual evaluation of LangGraph, a rapidly evolving library with features released after typical model training cutoffs for foundation models released in 2025. Our hypothesis is that models that have not seen these features during pre-training will struggle to navigate and use them. Tiles are a great alternative that can fix that!
We created the following experimental setup:
- Built a repository with several LangGraph pipelines to mimic real-world library usage.
- Created coding tasks that required recently released LangGraph features (see table below).
- Evaluated the Cursor CLI agent using two models (Auto and Sonnet 4.5), each run in two variants—with and without tiles (baseline) and repeated
10times for reproducibility. - Graded each run using targeted checks on setup hygiene, pipeline comprehension, StateGraph design, and core LangGraph implementation, following a curated evaluation rubric.
- Measured task accuracy as the proportion of checks passed, averaged across runs.
Our findings are summarized in the table below.
| Feature | Task (what we asked) | Feature Release Date | Pass ratio lift % with tiles for cursor-agent --model auto | Pass ratio lift with tiles % for cursor-agent --model sonnet-4.5 |
|---|---|---|---|---|
| Node caching | Enable a graph-level cache and per-node cache policies (for example, TTL, custom cache keys); demonstrate repeat inputs hitting the cache to skip expensive work. | Shipped May 29, 2025 | 8.2 | 14.5 |
| Deferred nodes | Wire a fan-in/aggregation node that executes only after all upstream branches complete (map-reduce or consensus style); show it triggers only once prerequisites are ready. | Shipped May 20, 2025 | 20.4 | 7.3 |
| v0.4 interrupts (HITL) | Adopt v0.4 semantics so invoke() surfaces interrupts; resume cleanly, including multiple interrupts, by mapping interrupt IDs to resume values; demonstrate an end-to-end human-review cycle. | Shipped April 29, 2025 | 19.4 | 12.2 |
Across all scenarios, we observe significant improvements in setups where agents had access to tiles, with performance increases ranging from 8.2% to 20.4%, indicating a better understanding of how to use libraries with newly introduced features.
Next steps and future work
In this work, we introduce Tiles — structured documentation designed for coding agents. Tiles provide the contextual knowledge needed to correctly use software libraries and their public APIs. They are publicly available through the Tessl Registry.
We evaluated tiles across ~270 popular open-source packages, testing how coding agents use them to solve real-world programming tasks. Our findings show that tiles significantly improve agent performance and output quality, with minimal computational overhead. Tiles provide a lightweight, scalable way to teach agents how to interact with the public APIs of any library or framework.
Tiles are especially valuable when using agents with newly released features of modern libraries, legacy repositories, and niche libraries that may not appear in the training data of major LLM providers such as Anthropic or OpenAI. Enabling Specs gives agents the ability to generate idiomatic, professional code that better utilizes library APIs, further enhancing engineer productivity.
In future work, we plan to evaluate tiles on larger problems and across multiple libraries, compare them with other context-augmentation strategies, and include metrics like unit-test pass rates, build success, and linter outcomes. We are also exploring retrieval optimization techniques to make tiles more token-efficient while preserving their accuracy gains, enabling faster and more cost-effective applications to real-world coding scenarios.
Citation
Please cite this work as:
Shaposhnikov, Gorinova, Willoughby, Knox, and Tessl AI Engineering, "A proposed Evaluation Framework for Coding Agents: Tiles Enhance Proper Use of Public APIs by ~35%", Nov 2025.Or use the BibTeX citation:
@article{abstraction-adherence,
title = {A Proposed Evaluation Framework for Coding Agents: Tiles Enhance Proper Use of Public APIs by 35\%},
author = {Shaposhnikov, Maksim and Gorinova, Maria I and Willoughby, Rob and Knox, Dru},
year = 2025,
publisher = {Tessl},
journal = {Tessl Blog},
urldate = {2025-11-12},
note = {\url{https://tessl.io/blog/proposed-evaluation-framework-for-coding-agents/}}}Appendix
Dataset
We are making the dataset of questions and criteria publicly available via the following Google Drive link. The archive contains an additional CSV file with the corresponding GitHub repository links, and links to publicly available tiles that can be downloaded from the Tessl registry here.


