

You still see posts like this all the time. A neat little prompt hack, a catchy framing, a sentence you can drop into CLAUDE.md or AGENTS.md, and apparently your coding agent suddenly becomes more careful and rigorous.
I get why these posts do numbers. Everyone wants the get-rich-quick version of agent unlock (AI engineers hate this one trick!). In 2025 AD, I was also scratching my own list of prompting techniques into papyrus. And at the time, that stuff really did help.
But today, these tips are misleading. They don't help the reader think about how to engage with agents in a productive way. And that's for a couple of reasons: firstly, the models are SMART now. We are officially in a post-strawberry era. And secondly, we now have actual durable systems which can get you the precise results you're looking for with high repeatability.
Putting prompt hacks to the test
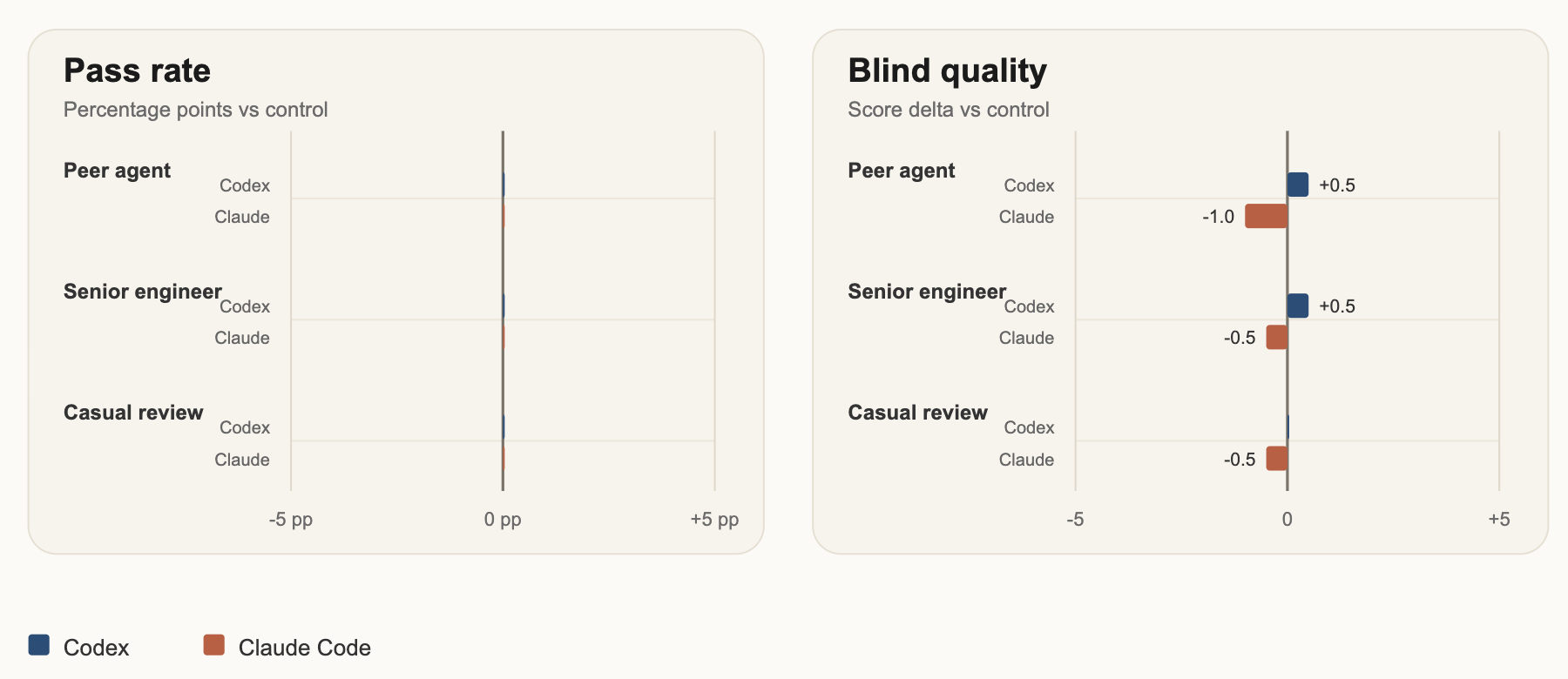
I ended up thinking about this again after seeing a LinkedIn claim that if you tell a coding agent another agent will review its work, the quality of its processes & output improve dramatically. That seemed easy enough to test, so I built a small eval around it. I gave the models tricky tasks, the kind notorious for making them flail on the details: template engine work involving tricky character parsing, and feature-rollout logic with nested rules, percentage bucketing, and hidden edge cases. I used four conditions: no mention of a reviewer, a "rival agent" will review this, a very senior engineer will review this, and a more casual “this will be reviewed". I tested Codex, Claude Code and Gemini across both tasks in all four conditions, then evaluated the results against hidden tests, build and lint checks, and a blind LLM review of the final code. Place your bets now.
{
"control": {
"description": "No explicit reviewer framing.",
"promptPreamble": "Complete the task carefully. Preserve existing public APIs unless the task explicitly requires otherwise."
},
"peer_agent_review": {
"description": "Another coding agent is said to review the work.",
"promptPreamble": "Complete the task carefully. Another coding agent will review your finished work after you are done. Preserve existing public APIs unless the task explicitly requires otherwise.",
"reviewerByAgent": {
"codex": "Claude Code will review your work when you're done.",
"claude": "Codex will review your work when you're done.",
"gemini": "Codex will review your work when you're done."
}
},
"senior_engineer_review": {
"description": "A highly capable human reviewer is said to review the work.",
"promptPreamble": "Complete the task carefully. A very senior engineer will review your finished work after you are done. Preserve existing public APIs unless the task explicitly requires otherwise."
},
"casual_review": {
"description": "A casual user-level review statement.",
"promptPreamble": "Complete the task carefully. I'll review your work when you're done. Preserve existing public APIs unless the task explicitly requires otherwise."
}
}...The results confirmed my original suspicions. On strong current models, this addition made no difference. None. Not in outputs, not in code quality, not in docs usage, not in token efficiency, not in LOC, not in correctness -- none of these metrics moved more than chance (which you'd expect from a stochastic system).
That doesn’t mean prompting does not matter. It does. A prompt tweak can still matter. Sometimes it matters a lot. But prompt tweaks are not durable systems. They are not especially transferable. They are often sensitive to the exact model, the exact task, the exact tool environment, and the exact moment in model history when you happen to test them.
That is not what I want from engineering. Instead I want something I can explain, test, reuse and improve over time. And lucky for me, Agent Skills provide this system.
Using Skills to build Durable Systems
If I want an agent to do a good code review, I would rather define what a good code review actually means, package that into a reusable skill, make it canonical, and evaluate it properly. Then the behaviour is visible, and repeatable. I do not have to guess whether the model is behaving today because I happened to phrase something the right way.
That is the big shift for me. The interesting work is not in collecting more little incantations. It is in building better context: skills, docs, rules, plugins, context artifacts, evaluators. Real systems.
Prompting is still part of that, obviously. But it is one part which is growing ever smaller. If you are still spending most of your energy on tiny phrasing tricks while ignoring the surrounding system, you are probably working on the least durable part of the problem.
So, yes, I think posts like this point at something real. Agents are sensitive to context. But the lesson is not “tell the bot its coworker is watching.” The lesson is that context is the product surface now, and we have much better ways to shape it than prompt hacking.
If you actually want a good code review, the better move is to define what good review means, encode it as a shareable skill, and make it part of the system. Then the behaviour is explicit. It can be tested, reused, and improved. You are no longer hoping the model responds to a cute bit of prompt theatre; you are giving it a concrete protocol to follow. If you want to try this in practice, Sentry’s code-review skill and Gemini’s code reviewer skill are both solid, well-eval'ed places to start.
