24 Feb 20267 minute read


Your AGENTS.md file isn't the problem. Your lack of AI Agent Evaluations is.
24 Feb 20267 minute read
A study dropped recently that's been making the rounds in developer circles, and the headline numbers are hard to ignore. Developer-written context files (AGENTS.md, CLAUDE.md, and their friends) improved task completion by just 4% on average. LLM-generated ones actually made performance worse by 3%. Both increased costs by over 20%. The conclusion from a video by the infamous Theo (t3.gg) that summarises the study lands on is, stop writing them, or at least stop generating them automatically.
I get why that framing is tempting. The data is real. But the conclusion is wrong, and it's wrong in a way that should feel very familiar to any developer who's been around long enough to hear someone say "our tests didn't catch the bug, so we're dropping the test suite."
Nobody says that. And nobody should say "context files didn't help, so delete them."
The REAL problem is that you're writing them blind
Think about what a context file actually is. It's a set of instructions, opinions, constraints, or patterns designed to shape how an agent behaves in your codebase. It tells it what tools to use, what patterns to follow, and what mistakes to avoid.
Now ask yourself, how do you know if those instructions are working or not?
Most people would have no idea. Perhaps some anecdotal evidence, but likely not much more than that. Typically, they would write the file, feel like the agent is behaving better, and ship it, before moving on to the next pressing issue. There's no measurement. No baseline. No way to know if the instruction telling the agent to always use withIndex in Convex queries is changing anything, or if it's just adding tokens and noise.
That's not a problem with the context files themselves. That's a problem with not having evals to validate them.
The study isn't proving that context is useless. It's proving that unvalidated context is useless, and often harmful. When you write instructions without a feedback loop, you end up with files full of things the agent would have figured out anyway (it reads your package.json, it explores your folder structure, it finds your schema), mixed in with instructions that are actively wrong or misleading. The model mentioned in the video kept reaching for tRPC in places it shouldn't because the context file referenced it. The developer knew it was a mistake. They just had no system for catching it.
Bad context files are like bad tests
When a test suite is poorly written, flaky, redundant, or testing the wrong things, it slows your team down. We end up losing trust in it. Some teams respond by gutting or skipping tests in the suite. Yeh, we’ve all been there.
The right move is to figure out which tests are providing signal and which are noise, and ruthlessly cut the noise. A lean, trustworthy test suite beats a bloated one every time. The goal isn't more tests. It's tests that tell you something true, and accurately.
Context files work exactly the same way. A 200-line AGENTS.md that the model ignores or misinterprets is worse than a 10-line file with three instructions the model reliably follows. The goal isn't more context. It's context that actually changes behaviour.
The question is: how do you know which is which?
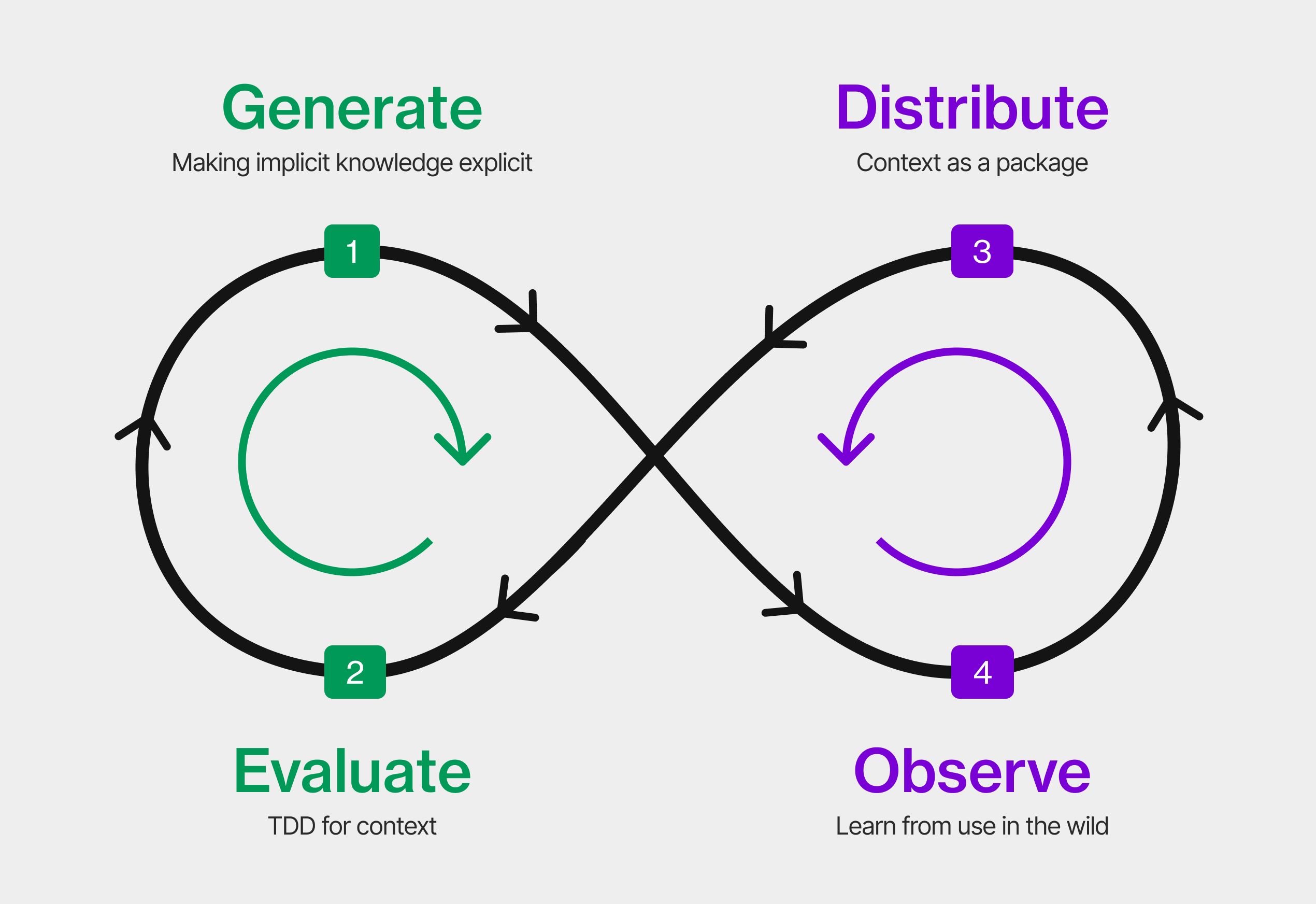
Agent Evaluations Are the Feedback Loop You're Missing
This is exactly where evals for agent skills come in. When you can run your agent against a set of defined tasks and measure whether it succeeds or fails, you suddenly have the ability to do something developers should be doing from day one: test your context.
Add an instruction. Run your evals. Did the pass rate go up, down, or stay flat? If it went up, the instruction is earning its place. If it stayed flat, you're adding cost and noise for nothing. If it went down, you just caught a bug in your context file before it shipped.
Strip out everything that doesn't move the needle. Keep only the high-signal, opinionated instructions, the ones that correct specific behaviours the agent wouldn't naturally get right on its own. You end up with a context file that is lean, validated, and actually working.
This is the workflow the ecosystem has been missing. Not "generate a context file and hope for the best." Not "delete your context files because a study said they don't help." Write context, measure it, cut what doesn't work, iterate.
Here’s an example of an ElevenLabs skill on the Tessl registry that shows review scores (validating how well a skill has been written against Anthropics best practices). Oh, there’s also suggestions of improvement to make the skill clearer to the agent, and increase activation.

Here’s another skill from Cisco with evals run, testing real-world scenarios, run by an LLM with and without the skill installed, showing a 1.79x improvement! And sharing where the context helped, made no difference, or hindered the agent. This allows us to improve, and make the context better!

Oh, you want to see more? Check out the pubnub suite of skills that have had evals run, and iterations of optimization, making them super valuable context that your agent should have to live without!

Still want to see more? Look for yourself on the Tessl registry!
The Right Conclusion From the Study
The study's finding that LLM-generated context files hurt performance makes complete sense through this lens. An auto-generated file is the worst of all worlds: it's full of information the agent could discover itself, it reflects no particular expertise about what the agent actually gets wrong in your codebase, and nobody validated any of it. Of course it underperforms.
But the answer isn't to abandon the practice. It's to bring the same discipline to context engineering that good developers bring to testing. Evals make that possible.
Don't delete your context files. Make sure they actually work. That should be a slam dunk for any developer who takes their AI tooling seriously.