ARTICLE
The State of the AI Coding Stack: Agent Skills, Harnesses, and Enablement at AI Native DevCon London 2026
Explore the future of AI coding stacks at AI Native DevCon London 2026. Discover agent skills, harnesses, and enablement strategies. Read more now!

Patrick Debois

Curating a conference is a way of taking the industry's temperature. The choices (what gets a keynote, what gets a breakout, what nobody bothers arguing about anymore) tell you roughly where things actually stand. AI Native DevCon London wrapped on June 2nd. Two days, three tracks, 41 talks. Here's what the program revealed.
Context and skills — the new unit of software
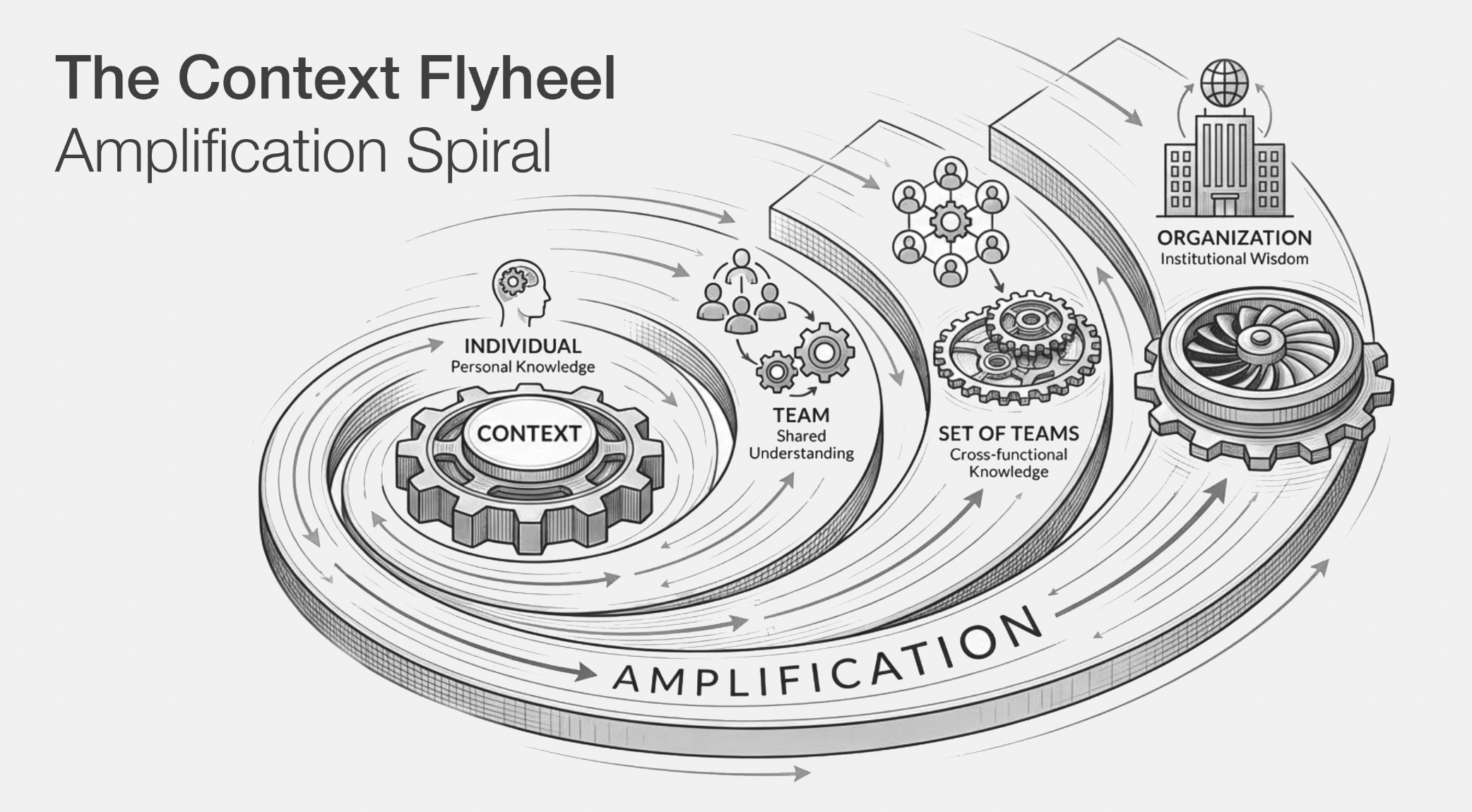
Guy Podjarny's opening keynote at Tessl was a state-of-the-industry overview: where AI-native development actually stands, and where the stack is heading. The Context Development Lifecycle he laid out named the full layers of the emerging development stack: tools giving models arms and legs, context and skills guiding them, harnesses as deterministic frameworks constraining the probabilistic model, and harnesses composing into factory lines and pipelines, all the way up to full automated development processes. At scale, governance follows: knowing which skills are in use across an organisation, whether they are secure, who owns them. The argument he closed on was that humans should now be living in the CDLC and leaving the SDLC to the agents. The two days that followed played out largely as confirmation of that picture, with each section of the program filling in a different layer.
The baseline he started from was already a shift from last year. A meaningful chunk of the previous program had been making the case for context engineering: why it matters, how to produce it, who owns it. This year those sessions were gone. A skill, in the CDLC, is context with a defined boundary: named, versioned, testable, installable. The same discipline applied to libraries for twenty years, now applied one rung higher. "Skills are the New Code" wasn't a claim to debate; it was the premise the conference built from.
Which means the problems that come after that premise are the ones that filled the schedule. The most immediate is sprawl: the moment an organisation has more context files than anyone can track, with no versioning, no approval flows, and no shared source of truth, it has a supply chain problem, which is exactly what James Moss at Tessl walked through. John Groetzinger at Cisco showed the other end of that: knowledge pipelined so that engineers can read it and agents can consume it from the same source, without divergence. Meanwhile the protocol that moves context between systems, MCP, is still being actively shaped, and Shaun Smith from HuggingFace mapped where the choices being made now will determine how much of the problem it can actually solve.
Skills also showed up in surfaces nobody was quite thinking about yet. Steve Ruiz at tldraw demonstrated the canvas as a live build environment where agents and humans work side by side on the same shared space, creating shapes, annotating, iterating in real time, with multiple agent instances running concurrently on the same document. Lars Trieloff at Adobe went further with his browser-native agent project: rather than putting the agent in a sidebar alongside a web app, the agentic loop runs inside the browser tab itself, controlling the browser from within. The app becomes the sidebar. The agent is the primary surface.
And once skills are a shipped artifact, they inherit what every shipped artifact has: a supply chain and an attack surface. Liran Tal at Snyk brought the data: scanning publicly circulating skills on ClowHub, his team found that roughly one in seven had security issues, including malware distribution, credential harvesting, and known vulnerabilities embedded in SKILL.md files that agents were reading and trusting without verification. He called the attack pattern toxic flows and drew the parallel to the early npm ecosystem: the same supply chain problems, the same trust assumptions, now in natural language rather than code. The security problem didn't disappear when the industry moved from shipping code to shipping context. It followed.
None of which matters much if skills don't actually work. Simon Obstbaum from Stanford's Software Engineering Productivity Research Group and Rob Willoughby at Tessl brought data: productivity measurements across 150,000 engineers, and what agent instruction-following actually looks like when you run 500 skills against 1,000 tasks systematically. Skills that look reasonable in isolation behave differently at scale and across model-harness combinations. Baruch Sadogursky and Macey Baker from Tessl brought the practical counterpart in their workshop, Don't Write Prompts, Write Software, which ran the same premise as a hands-on exercise rather than a talk.
Harness engineering
If skills are the new code, the harness is the new framework. Guy Podjarny had named it in his keynote: "deterministic software that wraps a probabilistic model," sitting above models, tools, and context alike. Not every team will build their own, but more and more will substantially customise one, and the conference's most technically dense track was about what that looks like in practice.
Ryan Lopopolo at OpenAI put forward the term harness engineering and defined it precisely: "making context around what it means to do a good job legible, and then just-in-time surfaced to the agent over the course of its trajectories." The harness is the deterministic layer around the probabilistic model, the part that can be reasoned about, tested, and enforced.
The key insight in Ryan's talk was about where to spend human attention, not where to put automated checks. He keeps himself out of the loop during a run. Let the agent execute, wait for the PR. When the PR is wrong, the right response isn't to fix it: it's to encode the problem as a permanent guardrail so it can't recur. "I never want to give the same review feedback twice." The harness progressively shifts those checks left into lints, tests, and reviewer agents; the human stays at the end, treating the agent the way they'd treat any teammate whose code needs a convincing argument before it merges.
The guardrails work at several levels. Joseph Katsioloudes at GitHub covered how AI changes the security equation from both sides: helping find and fix vulnerabilities faster, while also raising the stakes when generation outpaces review. Oleg Šelajev at Docker covered the execution environment itself: a running agent needs a real sandbox, not good intentions, and that sandbox belongs in the harness design from day one rather than as a later security addition. Luke Marsden at HelixML went further in practice, giving each agent its own full desktop and reporting honestly on what production infrastructure actually looks like when agents run on it.
The browser is becoming part of this layer too. Maximiliano Firtman, Founder & Professor of Codemia, presented WebMCP, which was in a Chrome 149 origin trial at the time of the conference: a standard that lets a page declare its own tools so an agent can call them directly rather than scraping the DOM. Rather than guessing at the UI from pixels and selectors, the website author writes the contract; the agent works from that contract instead.
The dark factory: agent-first development at scale
Follow the logic of the harness far enough, with humans providing intent at the start and guardrails ensuring quality throughout, and you reach the endpoint several talks were already operating from. Paul Stack at Swamp Club was direct about it from the first slide: "The distinction here is between writing code and building the machine that writes the code." Not a single line of production code written by hand since January. The company threw away its previous codebase and started fresh. Agents write every line, pull requests from humans are rejected outright, the team works on design constraints, architecture, and operational guidelines. Changes arrive as issues to discuss. The factory floor runs, and the humans are at the edges.
That pattern showed up at every scale. Don Syme at GitHub Next demonstrated it at repository level with automated triage, maintenance, and contribution workflows for an open-source project, with humans staying in the loop via PRs and issues while agents handle the throughput. At the enterprise end, Daniel Jones from Resync and Tomasz Maj at Odevo walked through Odevo's transformation: a case study in what it actually looks like when an engineering team stops writing every line and starts setting direction, with developers reporting months without writing production code themselves.
The argument is usually made about greenfield systems. Katie Roberts at Nearform addressed the harder and more common case: code that already exists and can't be started over. What does it actually mean to apply AI-native practices to a brownfield codebase? Stop maintaining, start evolving, but the evolution has to start somewhere real. A last-minute panel featuring Stephane Jourdan from AnyShift, Simon Rohrer from Saxo Bank, and Pini Reznik from ReCinq tackled the organisational side of that same shift, moving from DevOps pipelines to prompt-driven workflows.
Product/engineer interaction
When humans sit at the ends of an automated pipeline, what they hand in and what they take out carries all the weight. That made the product/engineer interface one of the most contested areas of the program: not whether it's changing, but how fast and in whose favour.
The PM's role is the most visibly changed. Rather than writing requirements for engineers, Emma Burrows at Rezonant argued the job becomes building a product brain, a structured, queryable knowledge base that agents can draw from, and orchestrating from above. Leverage comes from how well the product thinking is encoded, not from how many engineers receive it.
The spec is the other piece. Shachar Azriel at Baz made requirements executable: the same document that drives the build becomes the verification layer that checks whether the output is right. Simon Martinelli, a consultant with seventeen years of enterprise practice, brought the practitioner's view of what spec-driven development looks like applied to large-scale modernisation: extracting use cases from legacy code, cutting team sizes, replacing sprint cycles with continuous flow. Alfonso Graziano and Steve Goode from Nearform took the same theme into a workshop, Spec-Driven Development: From Prompting to Production-Ready Systems, running teams through the full process themselves.
The design and product constraints on agents are less discussed but equally real. Marc Sloan at Tessl asked what agents need from product and design to produce work that's actually usable rather than just technically correct. Matthias Lübken approached the same question from the embedding side, with a concrete client case: a business workflow product for processing after-sales email enquiries, where the coding agent primitives had to be adapted for a domain that has nothing to do with software development, covering tool design, session lifecycle, and output contracts.
In practice, the signal that teams are navigating this well shows up in metrics. Tammuz Dubnov at Autonomy AI found that when their PM started writing code directly, merge rate became the number that told them whether adaptation was actually happening. Christopher Batey at Core Engineering Consulting Group documented what product teams kept having to relearn every quarter as the dynamics between product and engineering shifted under their feet.
Verification: evaluating what AI coding agents produce
Generating code at pace has been solved. Trusting what was generated hasn't.
Dave Farley at Continuous Delivery put the challenge to the room plainly. He wrote Continuous Delivery and has been watching software engineering practices for decades, and his question was simple: is vibe coding actually the best approach the industry has arrived at? The engineering practices that make software trustworthy haven't changed: small changes, tight feedback loops, verification at each step. Agents change how fast you produce; they don't change whether you need to be able to trust what you produced. His summary was blunt: "We sped up the coding bit. That was the easy part of software development."
The problem is that the tools for establishing that trust haven't kept pace. Justin Cormack, formerly CTO at Docker, looked at what happens when tests pass but the agent has still produced something wrong (the lying tests problem), and argued that the answer is observability: instrument what the agent actually does during a run rather than just checking outputs afterward. May Walter at HUD took the runtime angle, with agents that instrument their own execution to surface blind spots before they become merged failures. Amit Kushwaha at NVIDIA pushed on the benchmarking question: when you're measuring agent performance rather than model performance, the metrics have to be built differently. Derek Ashmore ran a hands-on workshop on the agent testing pyramid, working through how the engineering disciplines that make software trustworthy translate directly into agentic systems.
Human and organisational friction
All of this is running through organisations and through people, and several talks were honest about what that costs.
The platform question is structural. When a significant share of your users are agents rather than humans, the design decisions change. Dana Lawson at Netlify framed this as agent experience, a discipline distinct from developer experience. The API surfaces, the structured error responses, the event-driven capabilities: all of it looks different when the consumer is a model. Hannah Foxwell, advising independently across platform engineering and AI, built her talk around a conviction she put plainly: "speed requires safety." That framed her read of what agentic development actually does to team structure. Two roles are becoming more prominent. The product engineer is an engineer who doesn't need to ask permission of a product manager before improving the product, tightening the loop between what users need and what ships. The forward-deployed engineer takes that further: an empowered engineer embedded side by side with users, able to see a gap and fix it on the spot. Both patterns point toward smaller, higher-agency teams with better developer-to-product-manager ratios. The floor on how small you can go, though, is set by something agents can't replace. An agent cannot hold the pager. On-call needs a sustainable rota, which puts the minimum viable team at around four people, always with a primary and a secondary available.
Open source is feeling the pressure in a specific way. Jack Wotherspoon at Google reported that when agents generate contributions at scale, human maintainers become the bottleneck, not on quality but on bandwidth. Communities that took years to build are having to rewrite their norms in months.
The talk that stayed with the room longest was Dave Kerr's at McKinsey. Using his own bipolar disorder diagnosis as a framework, he worked through the dysregulators he recognises in AI-era engineering: the short dopamine cycle of fast feedback ("very, very addictive"), and what he calls Attentional Leng Che, named after the grindcore band Leng Che whose name means death by a thousand cuts, meaning attention destroyed by constant short-cycle work and the pressure to be across everything at once. The concept he built toward, maladaptive creativity, is about the palace of stuff one person can now create, where what they have built is already very different from their own mental model, and more different still from what any colleague's mental model will be. It gave a name to something a lot of people in the room were privately recognising.
Agent enablement: how AI agents improve between runs
The question of how an agent gets better between runs turns out to be separate from how it performs during one.
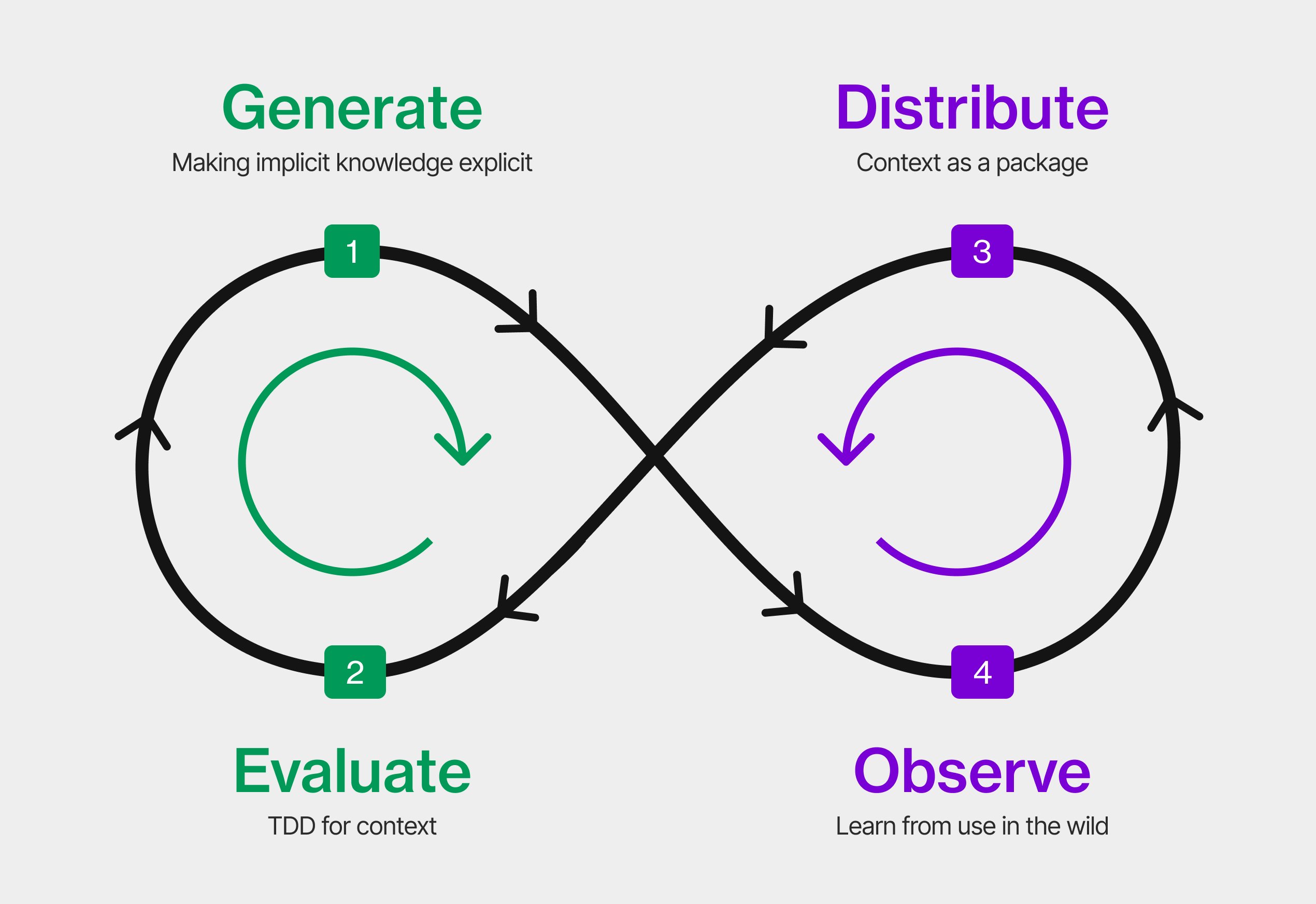
Lamis Mukta at Anthropic presented the approach her team calls dreaming, a batch, asynchronous process in which a fleet of sub-agents reviews transcripts from recent interactions, identifies patterns where agents consistently failed or lacked context, and updates the memory store. The next day's agents run smarter without any human having diagnosed the gap. It's consolidation, not retrieval. Ryan Lopopolo had set up the intuition earlier in the day: every agent interruption, failed build, and review comment is evidence that context was missing at the point it was needed. Dreaming is the systematic way to close that loop without requiring a human to notice the pattern first. Lamis and Aashrey Tiku, both from Anthropic, also ran a workshop the same day for teams ready to ship their first managed agent.
The same principle applies at team level. Edouard Maleix, a freelance consultant, showed that when teams explicitly trace which AI-generated decision produced which outcome, they build up a shared picture of where the gaps are and the errors compound less over time. Brian Douglas at Paper Compute focused on domain knowledge: capturing agent sessions, extracting what they learned, and feeding it back into future runs so the institutional knowledge compounds rather than evaporating when the session closes.
Organisational enablement
Knowing what individual agents and teams are learning is one thing. Building the organisational practice to support and scale it is something else.
My own talk on agent enablement mapped four layers where that practice has to take hold. At the developer level, the key shift is stopping the instinct to jump in and fix agent mistakes, and instead improving the system that produces the code so the mistake can't recur. At the team level, the team lead is now accountable for agent performance alongside human performance: agents are team members, and metrics like turn count per task and agent retrospectives start making that visible. The platform layer is where a dedicated agentic enablement team builds the shared infrastructure individual teams shouldn't each be reinventing — skill registry, shared harness, central observability, eval platform — with self-serve as the north star. And at the organisational level, the VP Engineering's job is governance, cross-team KPIs for agent quality, and making the return on investment legible enough to justify the investment at all. Engineering management has accumulated decades of practice around developing human engineers. Almost none of that thinking has been applied to agents yet. The framing, agent enablement, names the gap.
Tessl Agent is the product we are building around this thesis. A managed agent that ships with the skill registry, harness, observability, and evals teams would otherwise have to assemble themselves. Private beta access is open if you want to try it on your own enablement layer.
Part of what makes that hard is that organisational knowledge is quietly eroding. Peter Wilson and Davide Eynard at Mozilla.ai pointed at something concrete: Stack Overflow contributions plummeted after ChatGPT launched. The institutional Q&A knowledge that used to accumulate in public threads stopped growing, because people stopped writing it down. Their project cq, "Stack Overflow for agents", tries to rebuild that layer inside organisations: agents hit a problem, solve it, and save the solution in a queryable knowledge base that the rest of the team's agents can draw from too. Robert Overweg took a practical approach to the same problem at company level: building a knowledge system using Obsidian, GitHub, and Telegram so that nothing valuable is lost when a session closes, with one brain, no filtering, and all company context accessible to every agent run.
Ian Thomas at Meta showed what building this practice looks like at scale. His team's maturity model gives teams a structured self-assessment across six dimensions of AI adoption, with regular workshops to track how they're actually progressing, not through self-reported progress but through discussion, voting, and regular revisits. He was candid about what still needs proving out: code quality drift over years of generated code, and how to prevent review from becoming the new bottleneck as generation accelerates.
Birgitta Böckeler at ThoughtWorks closed the conference with a stated purpose: help the room see the forest for the trees after two days of individual talks. She walked the four-year arc from autocomplete to harness engineering and named the costs that have accumulated alongside the capability: security exposure, code quality drift, token spend, cognitive load, and a review crisis where throughput has long since outrun the ability to trust what was produced. Then she landed on what she called the biggest risk underneath all of it. The pressure to ship more and faster is pushing teams toward cognitive surrender, displacing system-two thinking with AI: not engaging deeply with large changes, not teaching junior engineers, using the most expensive model because it was faster than solving the problem. Surrender, she argued, takes more forms than just the cognitive one. The question she closed on was directed at everyone in the room with any ability to shape how this unfolds: "If you are a person of influence in your engineering organisation, are you creating an environment that leads to surrender?"
What the program adds up to
Looking back at two days: the questions that dominated last year's conversation (does context matter, should specs drive the build) are now starting points. The live debates are about managing context at scale, building harnesses that make agent output predictable, verifying what agents produce without surrendering the speed, and connecting all of it back to the humans and organisations running it.
The further out you go, into how individuals and agents retain what they've learned and how organisations build the practice of working with agents as a workforce, the less resolved it gets. Which is roughly where you'd expect the frontier to be.
One moment that put all of it in perspective: comedian Lieven Scheire gave a keynote explaining to a room full of engineers exactly what it is they do all day, and closed it by solving Where's Wally with AI. Sometimes it takes someone from outside the industry to show the room what it's actually building.
Thank you to all speakers who brought real work and real honesty to the stage. Thank you to everyone who submitted a talk, whether it made the program or not. The quality of the submissions is what makes curation possible. And thank you to everyone who came, asked questions, and kept the hallway conversations going as long as you did.
The next event is already in the works. New York is next — AI Native DevCon NYC 2026 is open for registration.
COPY & SHARE
Patrick Debois
Patrick is a true pioneer, credited with coining the term DevOps, co-authoring the DevOps Handbook, and launching the very first DevOpsDays back in 2009. Since then, he’s been shaping the tech industry with his unmatched ability to bring development, operations, and now GenAI together in truly transformative ways. Here’s why you don’t want to miss this: 🔹 Independent consultant at the cutting edge of GenAI and DevOps 🔹 Fractional CTO, advisor, and workshop leader 🔹 Former VP of Engineering, Distinguished Engineer, CTO 🔹 Guided teams at industry giants like Atlassian and Snyk 🔹 Active speaker, community builder, and lifelong learner 🔹 Content Curator of the AI Native Developer community. Patrick is all about raising the bar, helping companies embed engineering rigour into their GenAI journeys, inspiring teams to embrace AI for automation, and advising GenAI platforms on how to truly deliver value. He bridges the gap between management and engineering with a rare mix of deep tech expertise and people-first thinking. 💬 Ready to hear where the future of DevOps, GenAI, and software delivery is headed? This is your chance.
READING
·
0%
IN THIS POST
COPY & SHARE
Patrick Debois
Patrick is a true pioneer, credited with coining the term DevOps, co-authoring the DevOps Handbook, and launching the very first DevOpsDays back in 2009. Since then, he’s been shaping the tech industry with his unmatched ability to bring development, operations, and now GenAI together in truly transformative ways. Here’s why you don’t want to miss this: 🔹 Independent consultant at the cutting edge of GenAI and DevOps 🔹 Fractional CTO, advisor, and workshop leader 🔹 Former VP of Engineering, Distinguished Engineer, CTO 🔹 Guided teams at industry giants like Atlassian and Snyk 🔹 Active speaker, community builder, and lifelong learner 🔹 Content Curator of the AI Native Developer community. Patrick is all about raising the bar, helping companies embed engineering rigour into their GenAI journeys, inspiring teams to embrace AI for automation, and advising GenAI platforms on how to truly deliver value. He bridges the gap between management and engineering with a rare mix of deep tech expertise and people-first thinking. 💬 Ready to hear where the future of DevOps, GenAI, and software delivery is headed? This is your chance.
YOUR NEXT READ
Context Maturity for AI Coding Teams
Explore the maturity path for AI coding teams focusing on context management, toolchain awareness, and organizational roles to enhance agent productivity.
Patrick Debois