
AUTHOR
Rob Willoughby
Rob Willoughby is AI Research Lead at Tessl, where he leads the team building Tessl’s evaluation framework. He works at the intersection of applied AI research and product, focused on the question of how you actually know whether an agent is doing what you think it is. He’s previously worked on AIML systems across Apple, Twitter and Google DeepMind.
Articles
Article
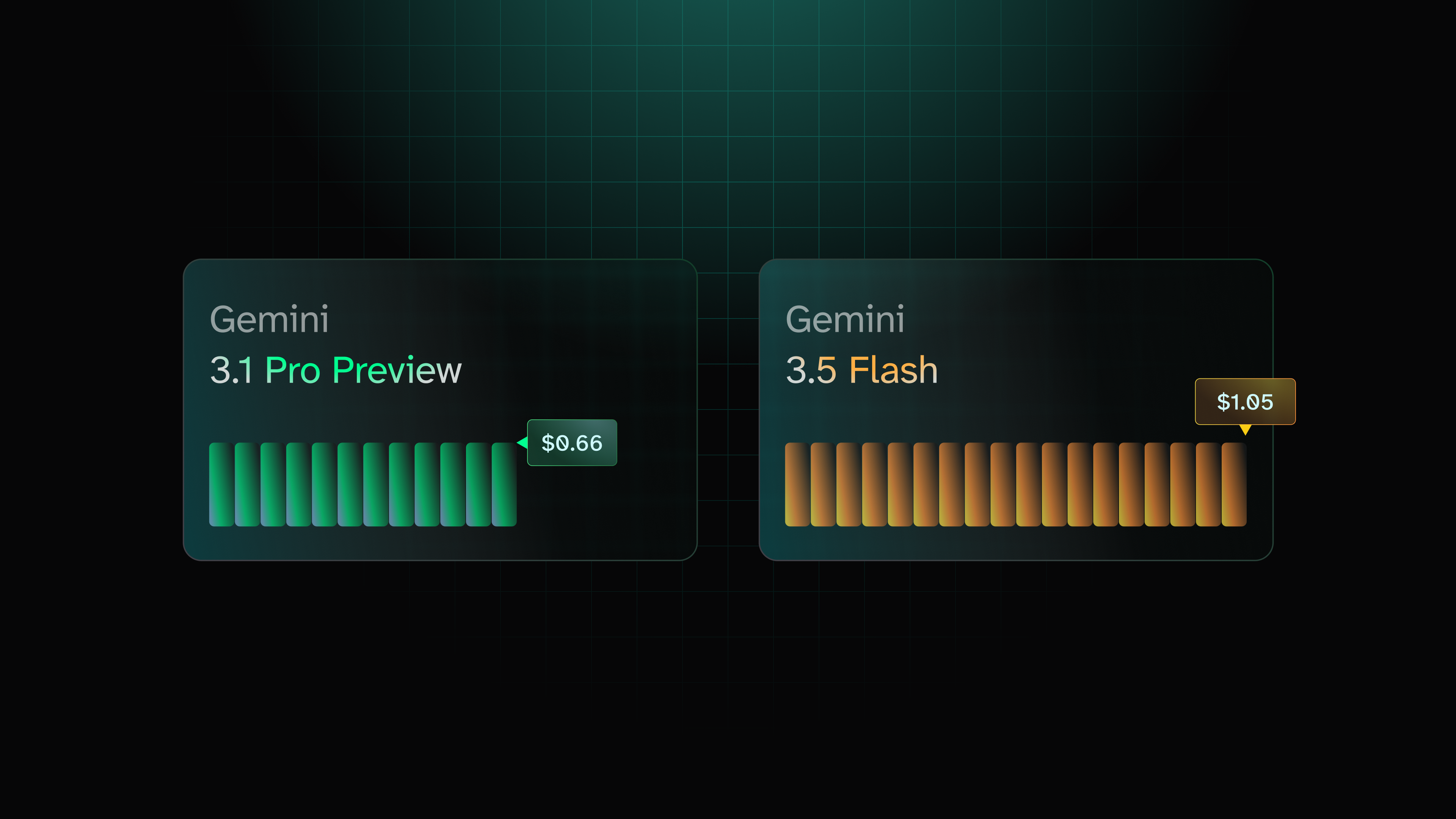
Why Your Gemini Bill Doesn't Match the Model Names
Gemini model billing discrepancies arise as task costs and model names don't align, with Gemini 3.5 Flash costing more than 3.1 Pro despite similar performance scores.

Article
Same quality, a quarter of the cost: Should DeepSeek Flash be your model of choice?
DeepSeek Flash offers comparable quality to pricier models at a fraction of the cost, making it a cost-effective choice for running agentic tasks at scale.

Article
AI Coding Agent Accuracy: Opus 4.7 vs 4.8
Opus 4.8 matches Opus 4.7 in accuracy but improves efficiency, solving tasks in fewer turns and at lower costs, highlighting differences beyond headline metrics.

Article
Why We're Changing Our Default Eval Model
The default eval model is changing from Claude Sonnet 4.6 to GLM 5.1 to reduce costs without losing signal quality, focusing on skill evaluation over model specificity.

Article
Evaluating Kimi 2.5 vs Kimi 2.6: What happens to agent skills when the model gets smarter?
Early signals from benchmarking Kimi K2.5, K2.6, and Sonnet 4.5 on 21 agent skills. Kimi K2.6 is a better model than K2.5, and skills still matter as models improve.

Article
A Proposed Evaluation Framework for Coding Agents: Tiles Enhance Proper Use of Public APIs by ~35%
This article proposes an evaluation framework highlighting how specifications enhance coding agents' effective use of public APIs, increasing code quality and efficiency by approximately 35% amidst evolving software interfaces.