ARTICLE
GPT-5.5 is OpenAI's best model. But paying more for it makes no sense.
Discover why GPT-5.5, OpenAI's top model, isn't worth the extra cost despite its capabilities. Explore performance vs. price in our detailed analysis.

Simon Maple
We added OpenAI’s gpt-5.5 model to our eval suite the day it launched. We ran 1,742 tests overall, which included over 45 task scenarios across using 11 real engineering skills, each run 6 times and averaged the data, which is shown in this blog.
TL;DR
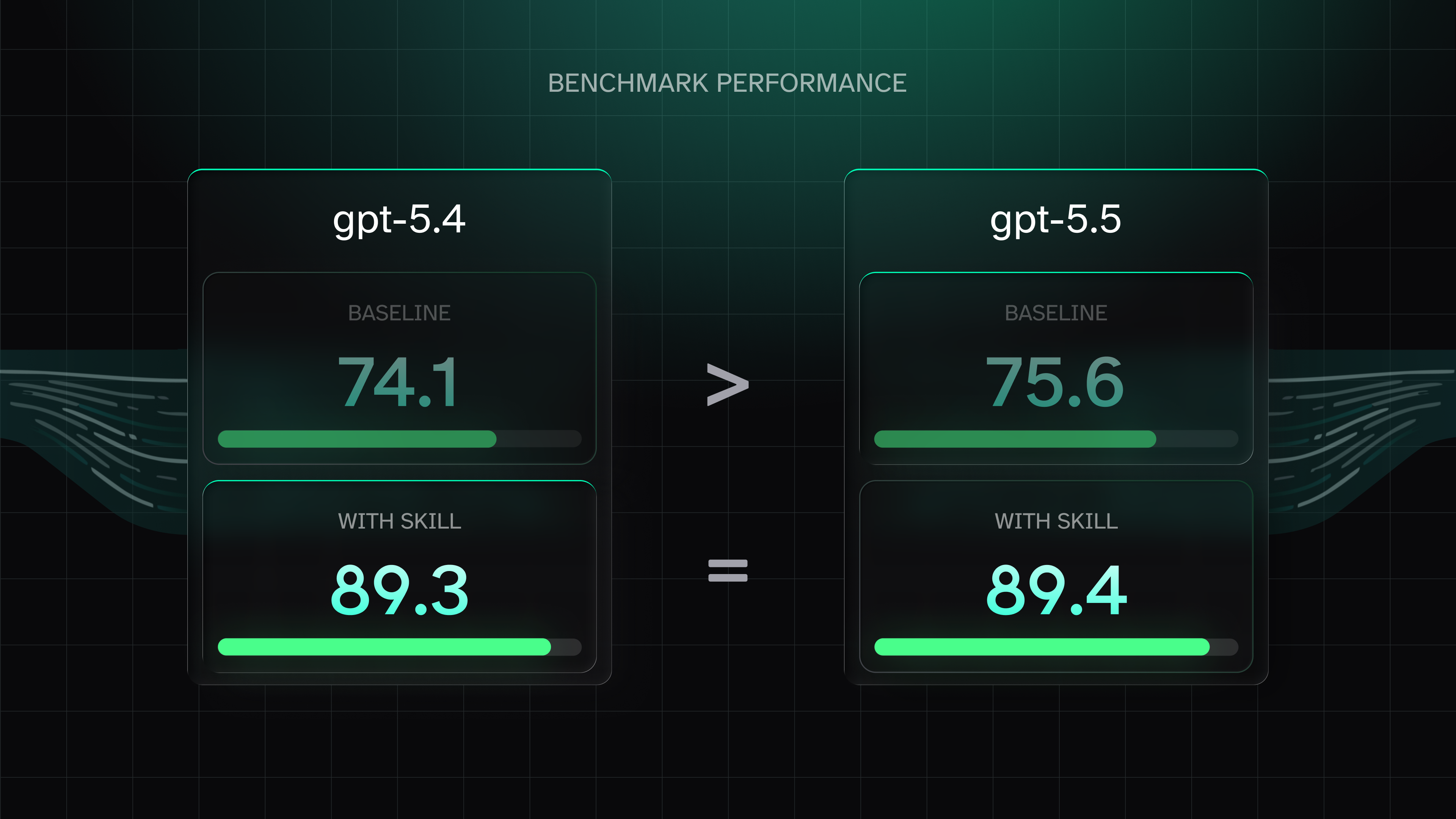
The gpt-5.5 model has the highest raw capability of any OpenAI model we've tested. When it uses agent skills and performs the same tasks, it pretty much ties with gpt-5.4 on score but costs 63% more per run.
| Question | Answer |
|---|---|
| Best Codex model out of the box? | gpt-5.5: 75.6 avg baseline, highest in the family |
| Best Codex model with skills loaded? | gpt-5.4 and gpt-5.5 tie at 89.3 and 89.4 |
| Worth the 63% price premium over gpt-5.4? | With this data, we don’t think so |
| Any scenario where it wins? | Latency: 89.5s vs 135.4s for gpt-5.4 |
| Should you use gpt-5.3 instead? | No, oddly enough, gpt-5.3 costs 47% more than gpt-5.4 for a worse result because of the token bloat. |
The one-line verdict: gpt-5.5 is the most capable Codex model we've benchmarked, and when using agent skills to guide with tasks, it performs pretty much identically to a model that costs a third less. The interesting story is actually gpt-5.3, which costs more than gpt-5.4 and scores worse, because of the token bloat in 5.3. The per-token cost is, of course, more expensive with gpt-5.5.
The Key Takeaways
The most counterintuitive thing in this data: gpt-5.5 and gpt-5.4 score within 0.1 points of each other when given domain skills, 89.4 vs 89.3. The self-sufficiency story holds directionally, but these two models are functionally the same on skill-augmented work. The question is purely cost.
The gpt-5.3 story is sharper. The headline numbers put it at 83.9 with skills against 89.3 for gpt-5.4, a 5.4 point gap. It also costs $0.44 per run against $0.30 for gpt-5.4. You pay more and get less, which is a complete description of a bad deal.
You pay $0.49/run for 89.4 points with gpt-5.5. You pay $0.30/run for 89.3 points with gpt-5.4. The only dimension where gpt-5.5 leads is latency, at 89.5s against 135.4s. If you're running latency-constrained agents and can absorb the cost, it's a defensible choice. Otherwise you're paying a 63% premium for 0.1 points.
How It Stacks Up
| Model | Task Scores (using agent skill) | Cost/run | Score/$ | Avg lift |
|---|---|---|---|---|
| claude-opus-4-7 | 93.4 | $1.00 | 93 | +12.6 |
| cursor:composer-2 | 89.6 | $0.23 | 389 | +15.4 |
| gpt-5.5 | 89.4 | $0.49 | 182 | +13.8 |
| gpt-5.4 | 89.3 | $0.30 | 298 | +15.2 |
| gpt-5.3-codex | 83.9 | $0.44 | 191 | +18.4 |
| gpt-5-codex | 78.7 | $1.05 | 75 | +10.0 |
gpt-5.5 and gpt-5.4 are functionally interchangeable on skill performance. The question is whether 45 seconds per run is worth $0.19.
What We Tested
This benchmark runs on Tessl, an agentic evaluation platform. A skill is a SKILL.md file, which is a structured markdown document containing rules, patterns, and examples for a specific domain. For the baseline run, the agent sees only the task prompt with no additional context. For the with-skill run, the SKILL.md is loaded into the agent's context alongside the task, same model, same task, same rubric. The score delta is the lift. The platform runs each scenario twice and scores the output against a pre-written rubric checklist automatically.
Each scenario was run 6 times and scored independently; all figures are averaged across those runs.
Why rubric checklists? Because the scenarios have objectively right answers. "Does the agent delete .eslintrc.json and create eslint.config.js?" is not a matter of opinion. Neither is "Does it use PKCE method S256?" or "Does it call pipeline() instead of chaining .pipe()?" Binary criteria eliminate evaluation noise wherever possible.
Example rubric: Modernize the Linting Setup for a Node.js Library, 11 criteria, 101 points.
| Criterion | Points | Pass condition |
|---|---|---|
| neostandard installed | 10 | neostandard present in devDependencies |
| standard uninstalled | 10 | standard absent from devDependencies |
| Flat config file | 10 | eslint.config.js or .mjs exists, not .eslintrc* |
| neostandard in config | 10 | Config imports from neostandard and calls neostandard() |
| lint script uses eslint | 10 | package.json lint script runs eslint ., not neostandard . or standard . |
| migrate command used | 10 | Instructions reference npx neostandard --migrate to generate the config |
| lint:fix script present | 8 | lint:fix script runs eslint . --fix |
| CI uses non-fix run | 8 | CI config runs lint without --fix |
| standard config removed | 8 | No top-level standard key in package.json |
| lint-staged uses eslint | 8 | Pre-commit hook runs eslint --fix, not neostandard or standard |
| eslint@9 installed | 8 | eslint at version 9.x in devDependencies |
A model that migrates the config correctly but leaves standard in devDependencies scores 91/101. One that creates eslint.config.js alongside .eslintrc.json instead of replacing it scores 0 on three criteria at once.
All skills and rubrics are published at simon/skills on the Tessl registry. Full eval results for this run can be found here.
The Data
Baseline scores (no skill), sorted by highest average
| Model | docs | fastify | init | lint | node | node-core | oauth | octocat | skill-opt | snip | ts | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| claude-opus-4-7 | 85.7 | 80.9 | 79.7 | 92.9 | 73.7 | 91.6 | 75.7 | 84.7 | 85.0 | 60.1 | 78.8 | 80.8 |
| gpt-5.5 | 89.9 | 71.8 | 63.6 | 94.4 | 64.6 | 72.3 | 73.6 | 85.5 | 83.2 | 54.7 | 78.3 | 75.6 |
| gpt-5.4 | 87.6 | 66.7 | 71.1 | 84.5 | 62.3 | 77.4 | 77.5 | 80.5 | 80.8 | 50.9 | 75.9 | 74.1 |
| cursor:composer-2 | 84.3 | 74.7 | 61.6 | 94.1 | 65.4 | 78.8 | 73.1 | 78.5 | 82.3 | 58.5 | 65.5 | 74.3 |
| gpt-5-codex | 80.2 | 67.3 | 60.2 | 84.9 | 60.4 | 76.5 | 72.9 | 75.3 | 63.8 | 47.5 | 66.5 | 68.7 |
| gpt-5.3-codex | 63.5 | 65.4 | 52.1 | 76.5 | 62.4 | 75.3 | 77.9 | 68.3 | 70.5 | 42.1 | 66.4 | 65.5 |
With-skill scores, sorted by highest average
| Model | docs | fastify | init | lint | node | node-core | oauth | octocat | skill-opt | snip | ts | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| claude-opus-4-7 | 96.7 | 98.9 | 82.3 | 97.2 | 95.1 | 84.7 | 94.3 | 97.7 | 99.7 | 92.9 | 88.0 | 93.4 |
| cursor:composer-2 | 95.6 | 93.9 | 85.7 | 96.4 | 94.0 | 92.3 | 83.9 | 94.5 | 93.7 | 85.3 | 70.4 | 89.6 |
| gpt-5.5 | 96.1 | 86.0 | 81.8 | 96.3 | 88.3 | 88.6 | 91.7 | 92.1 | 96.0 | 86.5 | 79.2 | 89.4 |
| gpt-5.4 | 97.1 | 76.9 | 80.0 | 98.1 | 84.8 | 93.7 | 91.6 | 95.7 | 94.6 | 90.9 | 79.0 | 89.3 |
| gpt-5.3-codex | 96.9 | 86.1 | 80.4 | 90.2 | 75.9 | 77.1 | 93.1 | 92.3 | 77.3 | 79.4 | 74.1 | 83.9 |
| gpt-5-codex | 62.9 | 88.9 | 74.8 | 92.1 | 66.3 | 77.7 | 89.3 | 85.9 | 80.7 | 86.0 | 61.1 | 78.7 |
Lift: what skills actually added per model, sorted by highest average lift
| Model | docs | fastify | init | lint | node | node-core | oauth | octocat | skill-opt | snip | ts | Avg lift |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gpt-5.3-codex | +33.4 | +20.7 | +28.3 | +13.7 | +13.5 | +1.8 | +15.2 | +24.0 | +6.8 | +37.3 | +7.7 | +18.4 |
| cursor:composer-2 | +11.3 | +19.2 | +24.1 | +2.3 | +28.6 | +13.5 | +10.8 | +16.0 | +11.4 | +26.8 | +4.9 | +15.4 |
| gpt-5.4 | +9.5 | +10.2 | +8.9 | +13.6 | +22.5 | +16.3 | +14.1 | +15.2 | +13.8 | +40.0 | +3.1 | +15.2 |
| gpt-5.5 | +6.2 | +14.2 | +18.2 | +1.9 | +23.7 | +16.3 | +18.1 | +6.6 | +12.8 | +31.8 | +0.9 | +13.8 |
| claude-opus-4-7 | +11.0 | +18.0 | +2.6 | +4.3 | +21.4 | -6.9 | +18.6 | +13.0 | +14.7 | +32.8 | +9.2 | +12.6 |
| gpt-5-codex | -17.3 | +21.6 | +14.6 | +7.2 | +5.9 | +1.2 | +16.4 | +10.6 | +16.9 | +38.5 | -5.4 | +10.0 |
Reading the lift table. A few observations:
- claude-opus-4-7
node-core: -6.9. Opus starts at 91.6 baseline on Node.js internals, the highest raw score on any skill for any model in the benchmark. Adding a skill that prescribes specific patterns for primordials and commit message format on top of a model that already knows the material produced interference, not uplift. The skill was written to close a gap that Opus doesn't have. - gpt-5-codex
docs: -17.3. The same skill that boosted gpt-5.3-codex by +33.4 points degraded gpt-5-codex by 17. The Diátaxis framework is highly prescriptive about structure: tutorial titles must start with verbs, reference sections must contain no instruction. gpt-5-codex starts at 80.2 baseline for docs, it produces fluent, correct-seeming prose, and the skill's structural constraints appear to actively conflict with its default output style. High baseline does not predict positive lift. - gpt-5-codex
ts: -5.4. Same pattern. A 66.5 baseline on TypeScript drops to 61.1 with the skill. The TypeScript skill enforces branded types and zeroany, rules that require restructuring code rather than extending it. For a model with established TypeScript habits, the prescriptive guidance appears to create noise rather than correct the specific gaps. - claude-opus-4-7
init: +2.6. The lowest positive lift in the table. Claude Opus is the model that introduced theAGENTS.mdconvention, it was already near-ceiling on this skill before any context was added. - gpt-5.4
snip: +40.0. The single highest lift cell in the entire dataset. snipgrapher's private CLI documentation gives a model that knows nothing a complete specification for a tool it's never encountered. gpt-5.4's strong instruction-following amplifies that advantage cleanly.
The cost of running gpt-5.5 vs the alternatives
| Model | Cost/run (with skill) | Time (with skill) | Score | Score/$ |
|---|---|---|---|---|
| cursor:composer-2 | $0.23 | 152.0s | 89.6 | 389 |
| gpt-5.4 | $0.30 | 135.4s | 89.3 | 298 |
| gpt-5.3-codex | $0.44 | 87.9s | 83.9 | 191 |
| gpt-5.5 | $0.49 | 89.5s | 89.4 | 182 |
| claude-opus-4-7 | $1.00 | 158.9s | 93.4 | 93 |
| gpt-5-codex | $1.05 | 136.2s | 78.7 | 75 |
More details about the 11 skills and scenarios
fastify-best-practices: Fastify has strong opinions, and the skill encodes them. Scenarios: Security Hardening for a Healthcare Web API (CORS scoped to two named origins, CSP + HSTS headers, HTTPS redirect, a wildcard * or a missing header scores zero); Authentication Service for a SaaS Platform (passwords migrated from bcrypt to argon2id, in-memory rate limiting replaced with Redis for multi-instance correctness, SIGTERM handled with close-with-grace); Protecting a Product Catalogue API from Overload (does it reach for @fastify/under-pressure or invent its own backpressure loop?); Order Management API with PostgreSQL (uses @fastify/postgres with correct pool lifecycle, not raw pg); Consistent Error Handling for a Multi-Tenant SaaS API (typed createError, uniform JSON shape, no stack traces to clients).
node-best-practices: The patterns in this skill diverge from what you'd find on Stack Overflow. Scenarios: Hardening Logging in a Fintech API (pino must redact auth tokens and raw card fields before they reach the SIEM, masking after the fact doesn't count); Webhook Receiver Service (structured logging of sensitive payment provider fields, graceful shutdown under concurrent in-flight requests); Fix Throughput Degradation in a High-Load API Gateway (dns.lookup() saturating the libuv thread pool, the fix is dns.resolve4() and UV_THREADPOOL_SIZE, not a caching layer); High-Throughput Merchant DNS Routing Service (concurrent resolution under load, observable thread pool saturation).
snipgrapher: A custom internal CLI with a non-public API. The model has never seen its documentation. At baseline, every model is essentially guessing (avg 50-60/100). With the skill, agents either follow the spec or they don't. Scenarios: Automating Changelog Snippet Images in CI (correct flag order, env var overrides, pipeline integration) and Code Snippet Image Pipeline for Documentation Site (batch rendering, profile configuration). This skill delivers the highest lift of any in the benchmark across every model, averaging between 27 and 40 points. The reason: it encodes knowledge that does not exist on the internet. Public skills are becoming less necessary as frontier models grow stronger. Private tooling is where skills still dominate.
typescript-magician: Not "add types to this function." Scenarios: Domain-Safe Payment Processing Types (branded types for AccountId, PaymentId, RefundId, plain type aliases don't count, as casts score zero); Product Catalog API for an E-Commerce Platform (TypeBox schemas inferred as TypeScript types end-to-end, internal cost fields stripped from public responses, no any); Eliminate any from a Data Pipeline Utility Library (tsc output captured before and after, zero any remaining, no @ts-ignore); Project Bootstrap: Node.js TypeScript Service (native --strip-types, no ts-node, no build step, no tsc in the start script).
oauth: Is the implicit flow explicitly removed? Is PKCE method S256? Is the refresh token replaced on rotation? Scenarios: Add User Authentication to a Fastify API (full Authorization Code + PKCE flow with @fastify/oauth2, state verification, token rotation); OAuth Login Integration for a Fastify Web App (CSRF-hardened flow, @fastify/session for state, correct cookie flags).
linting-neostandard-eslint9: ESLint v9's flat config is a breaking change. Scenarios checked whether agents actually migrated, not just created a new config alongside the old one. Is .eslintrc.json gone? Is standard removed from devDependencies? Scenarios: Modernize the Linting Setup (two variants: envparser open-source library and payments-api service); Add Linting to the Inventory Service (neostandard from scratch); Set Up Automated Lint Enforcement (husky + lint-staged pre-commit hook, CI step that blocks on violations).
documentation: Based on the Diátaxis framework. The skill teaches agents when to write a tutorial vs a how-to vs reference vs explanation. Scenarios: Restructure Documentation for a Configuration Library (sprawling confz README split into four Diátaxis types, tutorial title must start with a verb, reference section must contain no instruction); Getting Started Guide for a CLI Deployment Tool (shipctl onboarding tutorial with Goal→Prerequisites→Numbered steps→Verifiable result structure, no conceptual digressions in the steps).
init: Writing AGENTS.md / CLAUDE.md files that actually help AI assistants. Scenarios: Set Up Agent Instructions for a Growing Python Monorepo (3-year-old codebase, multiple service packages, identify the three constraints that cause the most agent damage); Set Up Agent Instructions for a Node.js Monorepo (workspace-aware package manager, per-package test commands, legacy directory exclusion); Audit and Slim Down a Bloated AGENTS.md (what to cut, what to keep, signal vs noise after a year of uncurated growth); Set Up Agent Instructions for a Growing Monorepo (hierarchical root-level vs per-package instructions, discoverability filtering).
octocat: GitHub CLI patterns and correct flag usage. Scenarios: Automate Feature Branch PR Submission (correct gh pr create flags, CI polling with gh run watch, merge only after checks pass); Preparing Commits for a Node.js Core Module Contribution (subsystem prefix, 72-char subject, Reviewed-By trailers, the format changelog toolbots parse); Prepare Node.js Core Contribution Commits (backport workflow, correct metadata for automated release pipelines); Automate Pull Request Workflow (reusable shell script, idempotent, surfaces CI failures before merge). nodejs-core: Contributing to Node.js core: primordials, commit message format, native addons with AsyncWorker. Scenarios: Product Catalog Caching Service (async-cache-dedupe, concurrency control to prevent thundering herd on a rate-limited upstream); Microservice Routing Layer: Latency Spike Investigation (diagnosing UV_THREADPOOL_SIZE exhaustion, dns.lookup() blocking the pool); Diagnose and Fix V8 Performance Regression in Analytics Processor (--prof, --trace-opt, reading isolate-*.log, acting on deoptimization reasons). skill-optimizer: Meta: given a poorly-written skill or benchmark report, improve it or interpret it correctly.
The Verdict
gpt-5.5 is a better model than gpt-5.4 on raw capability, and on latency it is not close. For everything else, they are the same model at different price points. Pay the 63% premium if you need the speed. Skip it if you care about cost or value per dollar.
The model to actually avoid is gpt-5.3. It costs 47% more than gpt-5.4 and scores 5.4 points worse. If you are running gpt-5.3 today, the case for switching to gpt-5.4 is strong on both cost and performance.
Frontier models are becoming more self-sufficient. The ROI on domain skills is concentrating in genuinely proprietary knowledge: your internal APIs, your custom tooling, patterns that simply aren't on the internet. Snipgrapher lifted every model by 27 to 40 points because no model had ever seen its documentation. ESLint v9 flat config lifted them by 2 to 14 points because capable models already know it.
COPY & SHARE
Simon Maple
Simon Maple is Tessl’s Founding Developer Advocate, a Java Champion, and former DevRel leader at Snyk, ZeroTurnaround, and IBM.
READING
·
0%
COPY & SHARE
Simon Maple
Simon Maple is Tessl’s Founding Developer Advocate, a Java Champion, and former DevRel leader at Snyk, ZeroTurnaround, and IBM.
YOUR NEXT READ
Same quality, a quarter of the cost: Should DeepSeek Flash be your model of choice?
DeepSeek Flash offers comparable quality to pricier models at a fraction of the cost, making it a cost-effective choice for running agentic tasks at scale.

Rob Willoughby, Simon Maple