
AUTHOR
Simon Maple
Simon Maple is Tessl’s Founding Developer Advocate, a Java Champion, and former DevRel leader at Snyk, ZeroTurnaround, and IBM.
Articles
















Article
The new Tessl review: now you decide what "good" looks like:
The new Tessl review lets users define their own criteria for skill quality, offers agent-based accuracy, and maintains a history of review runs.

Article
Same quality, a quarter of the cost: Should DeepSeek Flash be your model of choice?
DeepSeek Flash offers comparable quality to pricier models at a fraction of the cost, making it a cost-effective choice for running agentic tasks at scale.

Article
Opus 4.8 tops the LLM leaderboard with 95% on skill evals
Opus 4.8 leads the LLM leaderboard with a 95% skill evaluation score, surpassing Opus 4.7 and Composer 2.5 Fast, despite being the slowest model tested.
Article
We ran Composer 2.5 and 2.5 Fast across 11 skills. Surprisingly, Fast won.
Composer 2.5 Fast outperformed Composer 2.5 across 11 skills, scoring higher and running 32% quicker, while costing the same, challenging typical speed-quality trade-offs.
Article
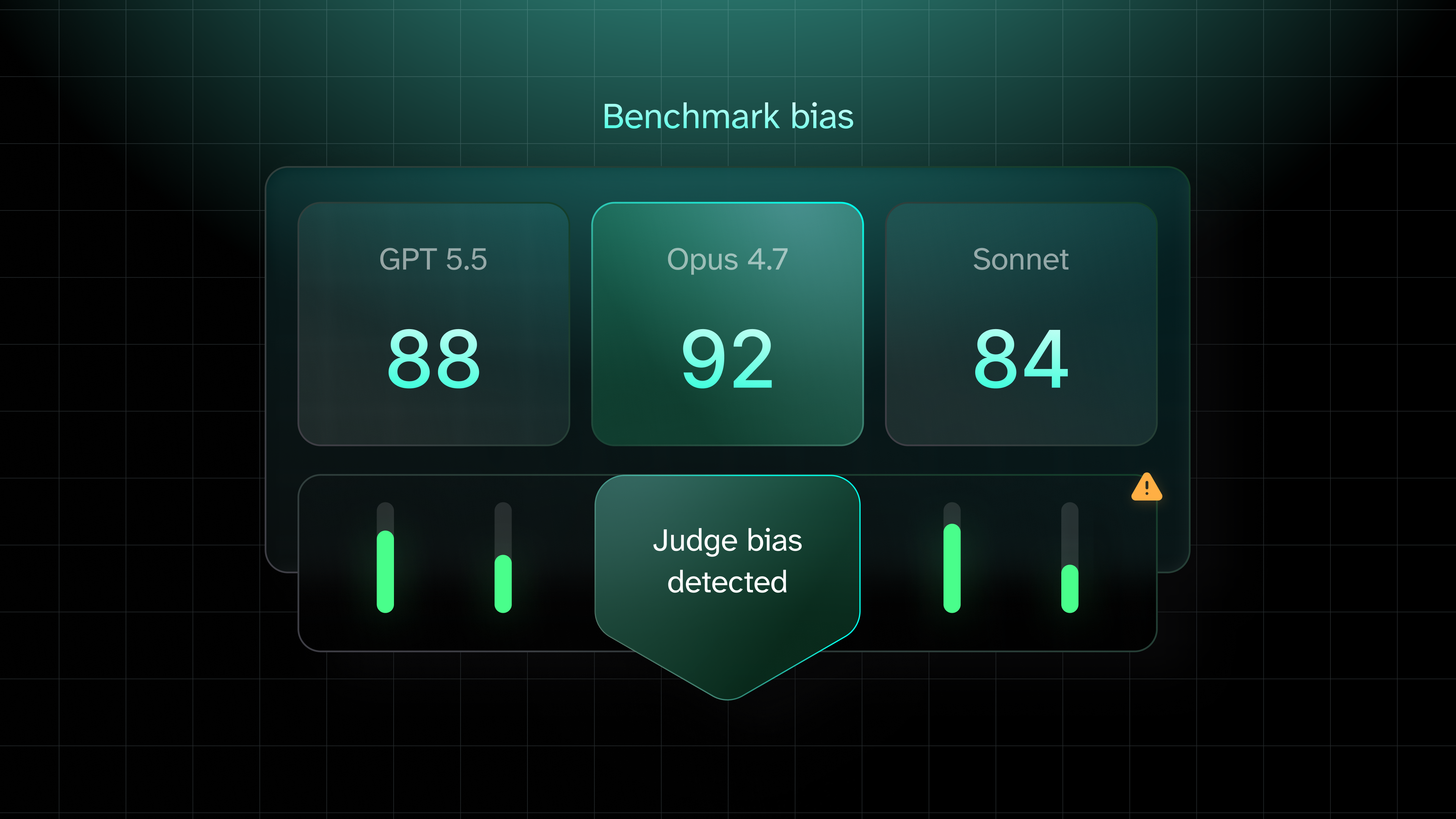
Your benchmarks are lying to you, and your judge is to blame!
Benchmarking AI models with single LLM judges can skew results due to judge bias. Multiple judges reveal score variations, suggesting a need for diverse evaluation methods.

Article
Stop trusting your agent skills with vibes. Eliminate the context security risk.
Learn how 'tessl-audit' helps secure AI agent plugins by scanning for vulnerabilities, assessing quality, and ensuring plugins enhance agent performance.
Article
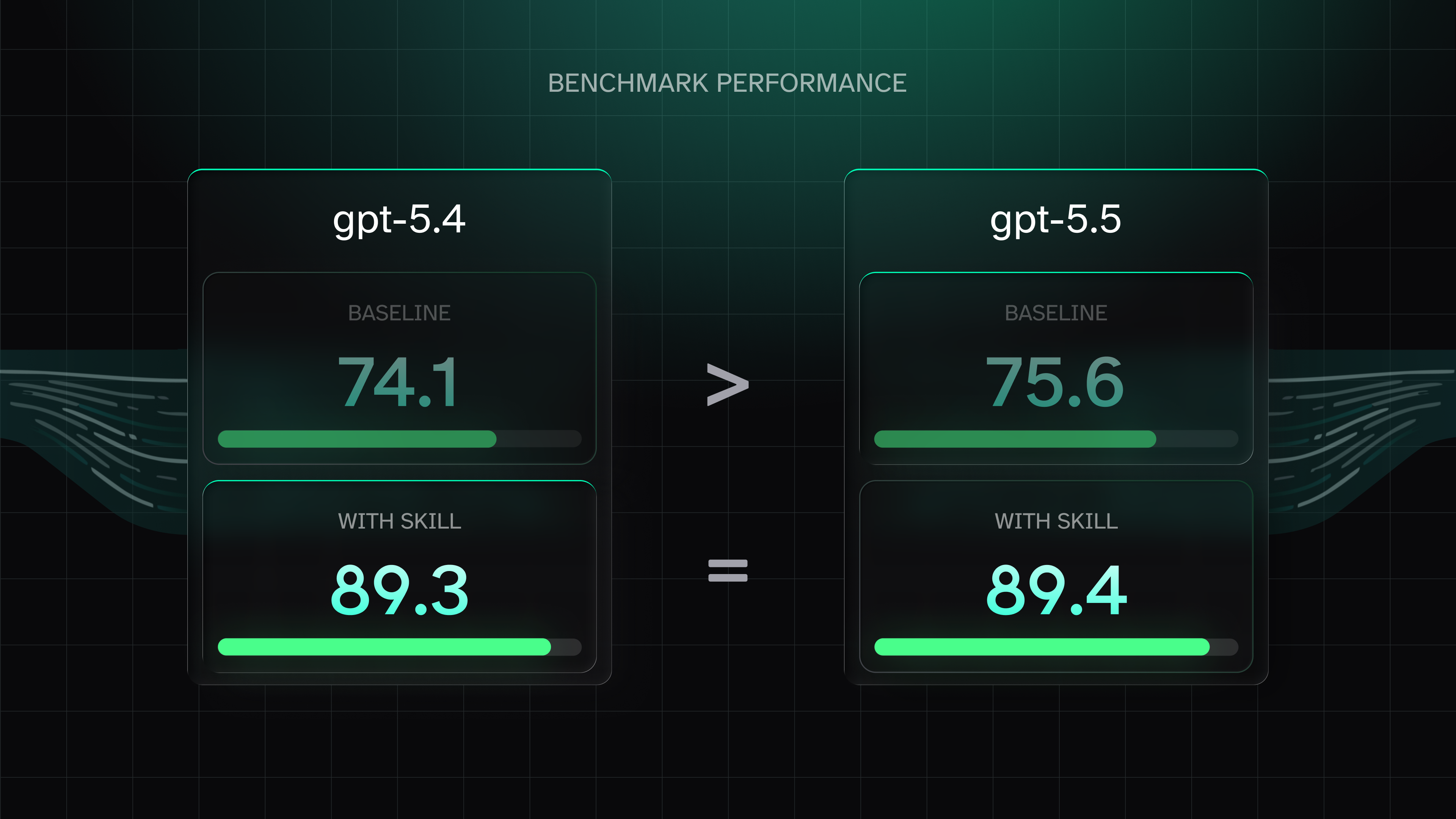
GPT-5.5 is OpenAI's best model. But paying more for it makes no sense.
GPT-5.5 is OpenAI's most capable model, but its 63% higher cost offers minimal performance gains over GPT-5.4, making it less cost-effective for most tasks.
Article
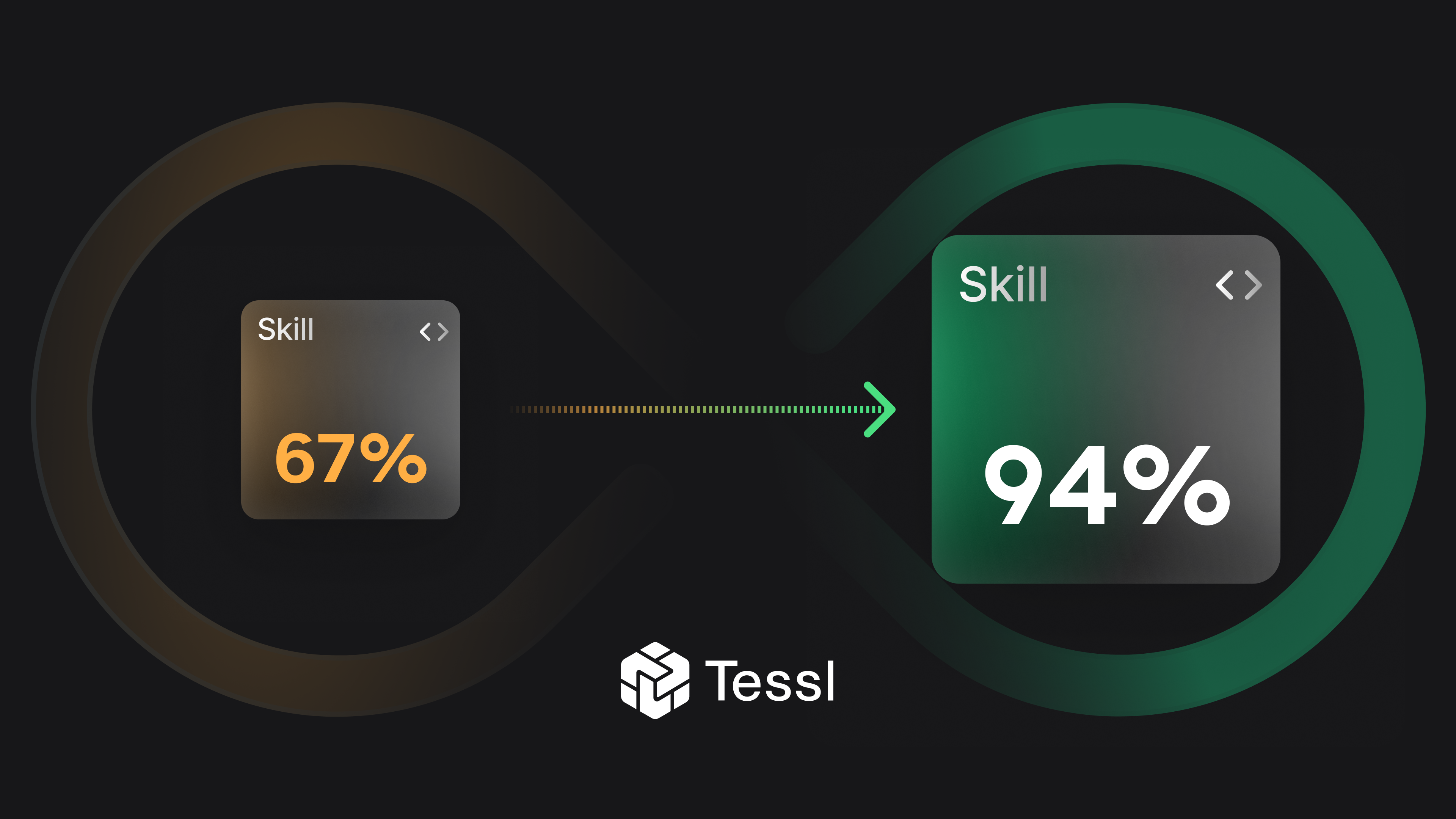
Stop guessing whether your Skill works: skill-optimizer measures and improves it
Skill-optimizer evaluates and enhances AI skills by running them through a judge-scored eval pipeline, providing measurable improvements and insights into skill performance.

Article
Anthropic, OpenAI, or Cursor model for your agent skills? 7 learnings from running 880 evals (including Opus 4.7)
Explore findings from 880 evaluations comparing Anthropic, OpenAI, and Cursor models, highlighting the impact of agent skills on performance and cost efficiency.

Article
The Tessl Registry now has security scores, powered by Snyk
The Tessl Registry now includes Snyk-powered security scores for skills, enhancing decision-making by assessing quality, impact, and safety before installation.

Article
What's new in Tessl: global installs, watch mode, GitHub badges, and a unified score
Tessl introduces global skill installs, automatic change monitoring with watch mode, GitHub badges for eval scores, and a unified score to represent skill quality.

Article
Your skill works on opus. Does it make haiku worse? Benchmarking AI skills across Claude models
Explore how the 'review-model-performance' skill benchmarks AI skills across Claude models, addressing compatibility and effectiveness issues in AI skill deployment.