ARTICLE
Opus 4.8 tops the LLM leaderboard with 95% on skill evals
Discover how Opus 4.8 tops the LLM leaderboard with a 95% skill eval score, surpassing Opus 4.7. Explore benchmark insights and model performance.

Simon Maple

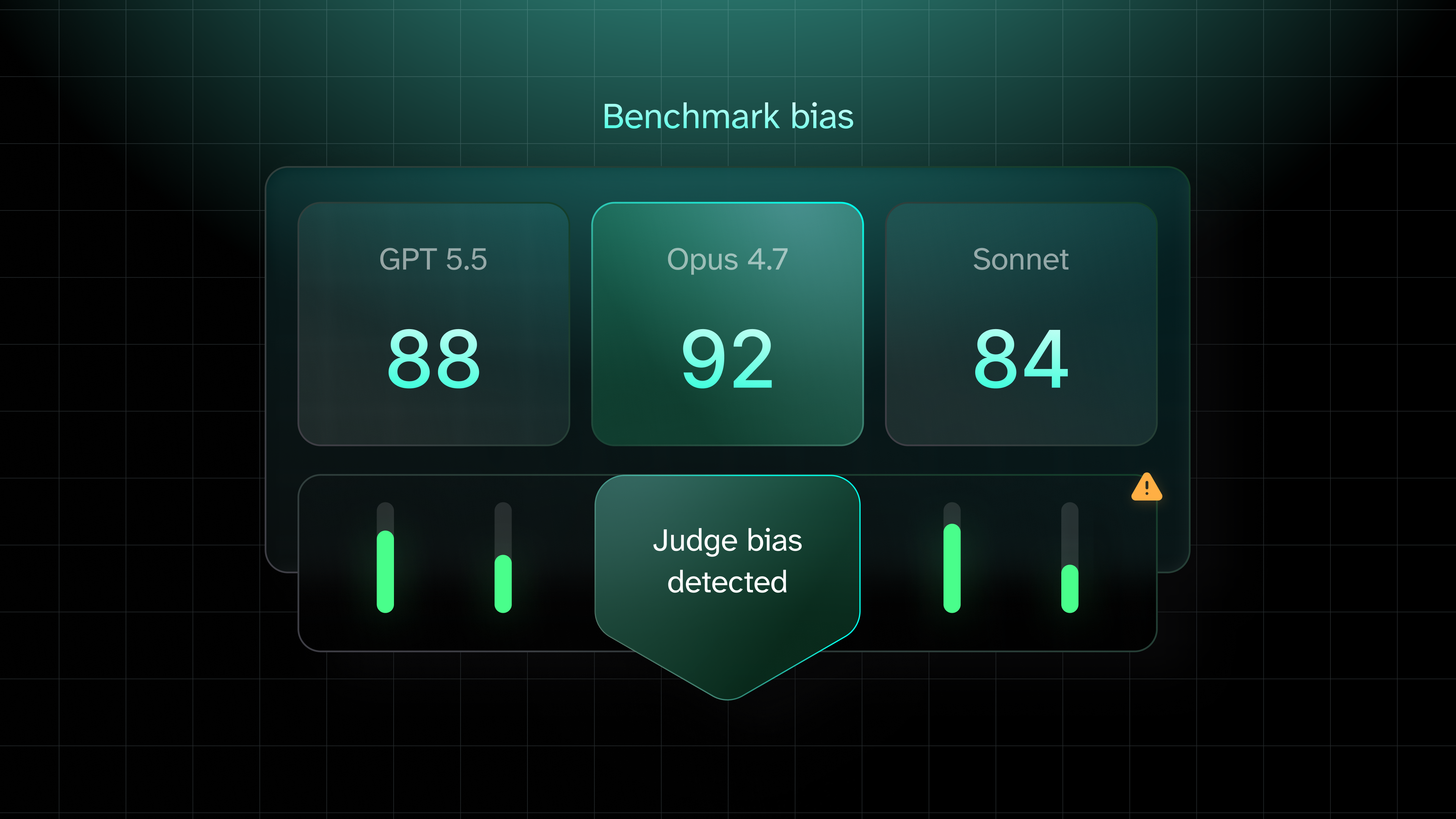
We added Claude Opus 4.8 to our ongoing model benchmark. It scored 95% with skill context, which puts it 1.6 points above Opus 4.7 and 2.3 points above Cursor's Composer 2.5 Fast. It is also, by a meaningful margin, the slowest model we have tested.
TL;DR
- Opus 4.8 scores 95% with skill context, taking the top spot from Opus 4.7.
- Its 81% baseline is the highest ever recorded in this benchmark, higher than every other model and remains top even when models run evals with skills loaded.
- All three independent judges agreed within two points, the tightest spread we have seen across nine models. Previous high-variance models swung over seven points between judges.
- On matched runs, Opus 4.8 takes roughly 671 seconds per eval. Composer 2.5 averages 327 seconds on the same pairs. Composer 2.5 Fast averages 215 seconds.
How the benchmark works
We test models against a set of engineering skills, each skill is a structured context document that tells an agent how to work correctly in a specific domain. The 11 skills in this benchmark cover: API documentation, Fastify server patterns, project initialisation, ESLint/neostandard linting, Node.js best practices, Node.js core contribution conventions, OAuth 2.0 security patterns, GitHub automation via the Octocat API, skill optimisation, code snippet rendering with Snipgrapher, and TypeScript configuration.
Each skill has five scenarios. Each scenario runs twice: once with the skill loaded (with-skill) and once without (baseline). That gives us the lift score (how much the skill context actually helps). Every run is scored independently by three LLM judges (Sonnet, GPT-5.5, and Opus 4.7), and we average the results. We covered why we use three judges, and what happens when you use only one, in a previous post. The short version: a single judge can swing results by over seven points depending on which model family it belongs to.
Where Opus 4.8 lands
| Model | Avg Baseline | Avg With-Skill | Lift |
|---|---|---|---|
| claude:claude-opus-4-8 | 81.0% | 95.0% | +14.0 |
| claude:claude-opus-4-7 | 80.8% | 93.4% | +12.6 |
| cursor:composer-2.5-fast | 79.6% | 92.7% | +13.1 |
| cursor:composer-2.5 | 79.0% | 92.1% | +13.1 |
| cursor:composer-2 | 74.2% | 89.6% | +15.4 |
| codex:gpt-5.5 | 75.5% | 89.4% | +13.9 |
| codex:gpt-5.4 | 74.1% | 89.3% | +15.2 |
| codex:gpt-5.3 | 65.5% | 83.9% | +18.4 |
| codex:gpt-5-codex | 68.7% | 78.7% | +10.0 |
Opus 4.8, Opus 4.7, and Composer 2.5 Fast are now meaningfully separated from the rest of the field. Everything below Composer 2.5 sits at 89-90% or lower, a gap of around 3 points that has been stable across our last several benchmark runs.
The baseline number
Opus 4.8 scores 81% without any skill context. That is higher than Composer 2.5, GPT-5.5, GPT-5.4, and every other model in the field even when those models have skills loaded. Every other model in this benchmark needs scaffolding to reach the floor Opus 4.8 starts from.
The implication for skill deployment is worth spelling out. Weaker baseline models get more absolute value from skill context because they need it more, gpt-5.3, for example, shows the largest lift at 18.4 points, starting from 65.5%. Opus 4.8 gets +14 lift, but it starts at 81%, which is a different category of floor. The skill is pushing a strong model further rather than compensating for a weak one.
Per-skill breakdown
| Skill | Baseline | With-Skill | Lift |
|---|---|---|---|
| linting | 99% | 99% | +0 |
| nodejs-core | 89% | 98% | +9 |
| skill-optimizer | 88% | 98% | +10 |
| fastify | 82% | 98% | +16 |
| documentation | 86% | 97% | +11 |
| octocat | 83% | 96% | +13 |
| oauth | 76% | 95% | +19 |
| node | 69% | 94% | +25 |
| snipgrapher | 58% | 94% | +36 |
| init | 78% | 90% | +12 |
| typescript | 81% | 86% | +5 |
Take a look at these skills here, including as the scenarios I ran against them.
Linting is near-perfect with or without skills, the rubric checks binary outcomes like whether a file was deleted or a package removed, which gives judges nothing to disagree about and leaves almost no room for the model to fail on the with-skill run either.
Snipgrapher is the outlier: a 58% baseline rising to 94% with skill context, a 36-point lift and the largest we have recorded for any model on any skill. Snipgrapher asks agents to follow a rendering specification they have never encountered before, so without the skill most agents approximate and with it they follow the spec. The gap is that large because the tool is genuinely obscure with no training signal for it.
Node best practices follows a similar pattern at +25. The baseline of 69% reflects how much the model has to infer from general coding knowledge alone. The skill provides the specific idioms and patterns that push the score to 94%.
The typescript result is the recurring problem. Both Opus 4.7 and Composer 2.5 showed a regression in this skill too: the model's own assumptions about TypeScript seem to conflict with the skill's guidance rather than build on it. At 81% baseline and only 86% with skill, Opus 4.8 gets just five points of lift where every other skill gets at least nine. The pattern is consistent enough across models that it points to a skill design problem rather than a model problem. If TypeScript configuration is central to your workflow, this is worth investigating before deploying.
The judges agreed, which is unusual
In the judges post we documented a 7.3-point swing for Opus 4.7 across the three judges, with GPT-5.5 grading it at 89.2% and Opus giving itself 96.5%. We attributed the high Opus-as-judge score partly to self-judge bias. Opus gave itself a 4.6-point boost over what the other judges awarded.
For Opus 4.8 the spread was just two points: Sonnet gave it 96%, Opus 4.7 gave it 95%, and GPT-5.5 gave it 94%. That is the tightest cross-judge agreement we have seen for any model in this benchmark. A strict judge and a generous one converge when the answer leaves no room for interpretation. Opus 4.8 got there more consistently than any model we have tested, which is why the judges stopped disagreeing.
This also has an implication for eval cost. A model that produces consistently unambiguous outputs could potentially be scored with a single strict judge without much risk of inflation. You would still want to verify that for your specific rubrics, but the data suggests the three-judge overhead is less necessary here than it was for previous models.
It is slower, and that cost compounds
We measured timing on matched skill and judge pairs. These are the same scenarios and judges for both models, ensuring we give a fair comparison. Opus 4.8 averaged 671 seconds per eval run. Composer 2.5 averaged 327 seconds on the same pairs and Composer 2.5 Fast averaged 215 seconds, roughly two to three times faster.
For a one-off task the latency barely registers. In an agentic loop over hundreds of sequential tasks, Composer 2.5 Fast completes three full runs in the time Opus 4.8 finishes one, and that gap turns into hours at scale.
Pick it when task accuracy has downstream consequences. When throughput is the binding constraint, Composer 2.5 Fast is three times faster and only 2.3 points behind.
How these numbers were produced
Every score in this post is averaged across three independent judges: Sonnet, GPT-5.5, and Opus 4.7. We do not publish single-judge scores. The Opus 4.8 runs used the same 11 skills and 5 scenarios per skill as every prior model in this benchmark, so the comparison is direct.
COPY & SHARE
Simon Maple
Simon Maple is Tessl’s Founding Developer Advocate, a Java Champion, and former DevRel leader at Snyk, ZeroTurnaround, and IBM.
READING
·
0%
IN THIS POST
COPY & SHARE
Simon Maple
Simon Maple is Tessl’s Founding Developer Advocate, a Java Champion, and former DevRel leader at Snyk, ZeroTurnaround, and IBM.
YOUR NEXT READ
The new Tessl review: now you decide what "good" looks like:
The new Tessl review lets users define their own criteria for skill quality, offers agent-based accuracy, and maintains a history of review runs.
Simon Maple