ARTICLE
Claude Fable 5 vs Opus 4.8: The Mythos Hype Meets Reality
Discover if Claude Fable 5 lives up to the Mythos hype against Opus 4.8. Explore the capabilities and decide which model suits your coding needs best.
For months, the most interesting model at Anthropic was one we could not use. Mythos was the internal system the company said was too capable to release, the one that found software vulnerabilities at a level that tripped its own safety thresholds. On June 9, 2026, that tier went public for the first time, as Claude Fable 5. Opus 4.8, the model anchoring production coding agents, suddenly had a successor that's a full capability class above it.
This raises two questions for anyone running coding agents. The practical one is whether you should move your fleet from Opus 4.8 to Fable 5. The bigger one is whether a Mythos-class model, the tier Anthropic held back as too capable to ship, lives up to what the name promised. This article answers both, and the numbers tell a more interesting story than the announcement did.
We ran both models through the same evaluation, close to 1000 shared scenarios scored twice each, once with no skill supplied and once with the relevant skill in context. The short answer, as of mid-2026, is that Opus 4.8 is still the better value for most agent fleets, and the gap between the Mythos hype and the measured reality is the real story in the data.
A Mythos-class model is a tier of Claude that sits above the Opus class in capability. It reaches a threshold Anthropic considers high-risk, particularly at discovering and exploiting software vulnerabilities. Fable 5 and Mythos 5 are the same underlying model with the same capabilities. What separates them is the safeguards: Fable 5 is the public version that ships with safety classifiers, while Mythos 5, restricted to approved partners, runs without them.
What the industry expected from a Mythos-class model
Before launch, the speculation was not subtle. Across Reddit, X, and a run of explainer posts, Mythos was framed as the model that would change how agents work, not just how well they answer. The recurring predictions clustered around four capabilities:
- Restructuring a large codebase in one coherent pass.
- Spotting security flaws that experienced engineers miss.
- Working unsupervised for hours on a single hard problem.
- Acting like a collaborator, not an assistant you steer turn by turn.
Of the four, the cybersecurity claim was the one with hard evidence behind it. Through Project Glasswing, roughly 50 early partners with Mythos Preview access reported finding more than 10,000 high or critical severity vulnerabilities, and the program has since expanded past 150 organizations. Anthropic's CPO Mike Krieger called it "the most capable class of systems we've built." That is the dream the name sold: a model so powerful it stayed in the lab.
What reached the public is narrower, and deliberately so. The model you can actually use is Fable 5, the Mythos-class system wrapped in safety classifiers. Whether it delivers comes down to the gap between that promise and what was released.
The headline numbers: Claude Fable 5 vs Opus 4.8
Every scenario in the evaluation is a real agent task tied to a published skill, scored on two axes: instruction-following (does the agent do what it was told, in the way it was told) and task-completion (does it reach the goal). The overall score weights instruction-following at 4 and task-completion at 3, then divides by 7. Each task runs with and without the skill, so the lift from the skill is visible directly. The tasks and skills are public, in the task-evals-for-skills dataset, so you can inspect any scenario yourself.
This design is deliberate. The tasks come from published skills, so they mirror the real work teams write skills for, not frontier puzzles meant to find a model's ceiling. That is why task-completion runs high for both models and why the signal that separates them is instruction-following: doing the work the specific way the skill asks.
| Dimension (with skill) | Fable 5 | Opus 4.8 |
|---|---|---|
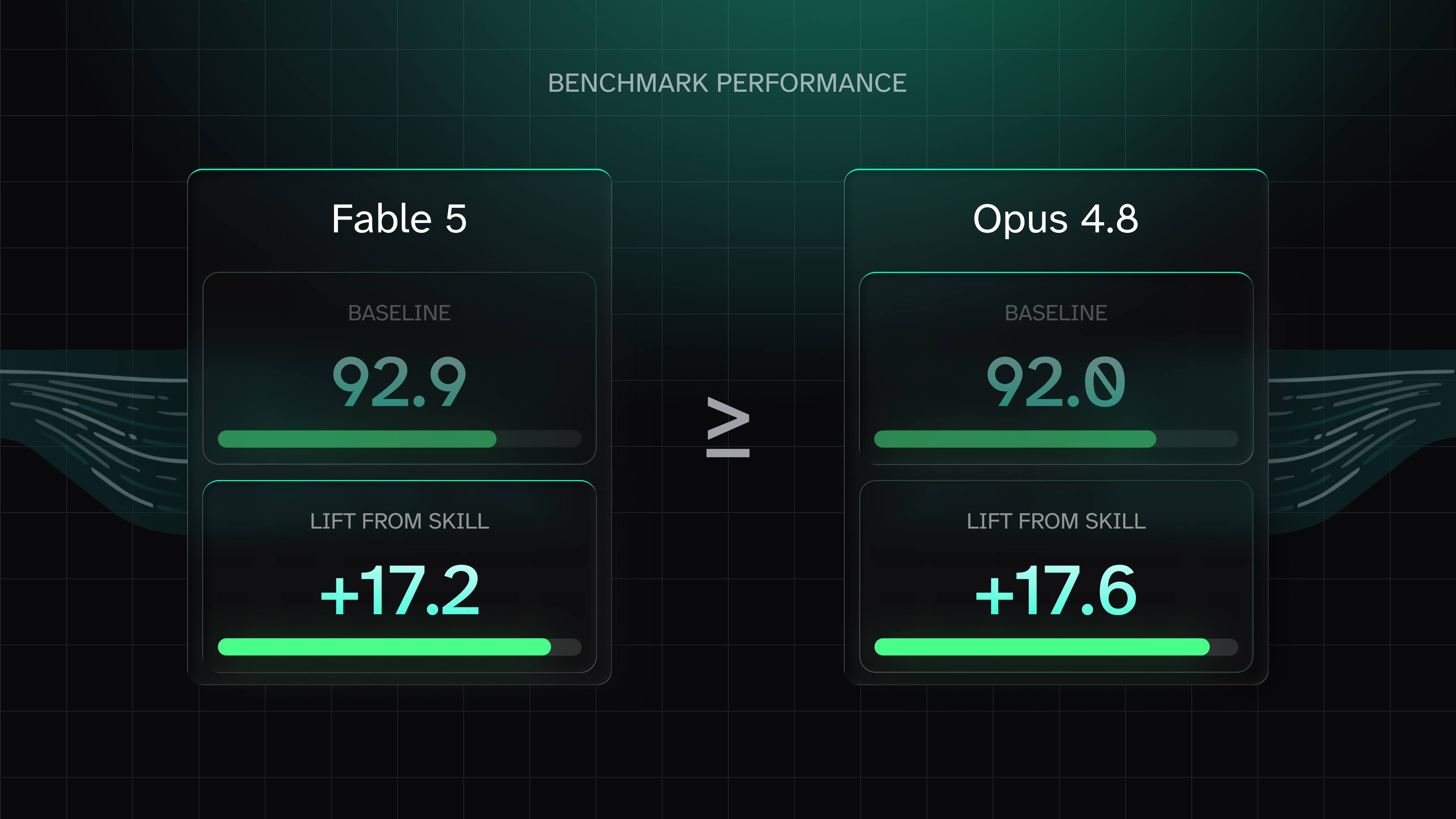
| Overall score | 92.9 | 92.0 |
| Overall score (no skill, baseline) | 75.7 | 74.5 |
| Overall lift from the skill | +17.2 | +17.5 |
| Instruction-following | 89.3 | 88.0 |
| Task-completion | 97.8 | 97.4 |
| Turns to complete | 16.9 | 16.2 |
| Output tokens per task | 9,025 | 10,687 |
| List price (input / output, per MTok) | $10 / $50 | $5 / $25 |
| Cost per task (average) | $1.25 | $0.74 |
| Points per dollar | 74 | 125 |
On the 917 scenarios both models ran, Fable 5 leads on overall score by 0.9 points (92.9 to 92.0). Scenario by scenario, the two tie on 61% of tasks, Fable wins 24%, and Opus wins 16%, at a two-point threshold. A capability class above Opus, and on everyday agent skill tasks the quality difference is inside the noise.
One caveat sits underneath that number. The 917 are the tasks both models completed and scored. Fable 5 refused 26 that Opus 4.8 finished, and we excluded them, so the near-tie is measured only on the tasks Fable agreed to do. That exclusion turns out to be the most revealing part of the comparison, and we return to it below.
Why agent skill evaluation matters more than the model upgrade
Here is the number that reframes the comparison. The skill adds about 17 overall points to both models: +17.2 for Fable 5 and +17.5 for Opus 4.8. The model upgrade from Opus 4.8 to Fable 5 adds less than 1 point on shared tasks. The context you supply moves the agent far more than the frontier tier you pick.
The lift concentrates in instruction-following, where both models gain more than 27 points from the skill, while task-completion gains under 5. Both models can usually reach the goal on their own. What they cannot do reliably without a skill is follow the specific conventions, constraints, and steps a real task demands. That is what a good skill encodes.
Skill receptivity is how much an agent's output improves when you supply a relevant skill. It shows up mostly as better instruction-following. It matters because it can outweigh the model choice, which is the practical case for investing in agent skills before chasing the newest tier. Running the same task with and without the skill, then measuring the difference, is a task eval. It is also the only way to know whether a model upgrade earns its price on your workload, which is what agent skill evaluation is for.
The price gap is the deciding factor for most teams
On the agent skill tasks we measured, the trade comes down to paying a steep premium for a marginal gain. Fable 5 lists at $10 per million input tokens and $50 per million output tokens against Opus 4.8's $5 and $25, exactly twice across every token category, including cache reads and writes. For that, across our 917 shared scenarios, you get an overall score of 92.9 versus 92.0, a 0.9-point edge that sits well inside the range where the two are interchangeable. This is the everyday-agent-work picture, not a verdict on the marquee Mythos capabilities our eval does not test.
Token behavior softens the unit price but does not close it. Across the 917 shared scenarios Fable 5 generated about 16% fewer output tokens per task (9,025 versus 10,687), so the real cost per task lands at $1.25 against $0.74, a 73% premium rather than a clean 2x. The value gap is the number to remember: Opus 4.8 returns 125 points per dollar to Fable 5's 74, about 69% more quality for every dollar spent.
For a single session the difference is cents. For a fleet running thousands of agent tasks a day, it is the line item your finance team will ask about, and twice the price for under a point of quality on the tasks most teams actually run is not an easy answer to give them.
Fable refuses work Opus completes without issues
The most consequential difference between Fable 5 and Opus 4.8 is not on the scoreboard. It is the safety layer that defines the Mythos class.
Fable 5 ships with safeguards covering four domains: cybersecurity, biology and chemistry, distillation, and frontier LLM development. For the first three, a triggered request comes back as a refusal. Anthropic's design hands it to Opus 4.8 and informs the user, but that fallback is opt-in rather than a default, so in a stock harness like ours the blocked requests simply refused.
The fourth domain worked differently during this run. By Anthropic's own documentation, requests touching frontier AI development were not refused or even flagged. The model quietly steered or fine-tuned its answer instead, with no notice to the user. That silent manipulation drew the sharpest backlash, and on June 11, the day after this run, Anthropic switched it to a visible classifier like the other three while conceding the restrictions had been "overly conservative." Because it never produced a refusal, that domain leaves no mark in our numbers; any effect would surface only as quietly weaker answers.
A Mythos-class model routes some requests to a weaker model by design, so your harness needs to detect the fallback rather than trust that every response came from Fable. And the affected domains are exactly the ones you most want to check yourself, which is the practical edge of context governance and security: catch the regression in an eval, not in production.
Our run shows how that plays out, and it is not flattering. Fable 5 refused 26 of the roughly 940 tasks it attempted, returning a usage-policy block with a refusal stop reason instead of doing the work, while Opus 4.8 completed and scored every one of them. What Fable refused is the revealing part. Four were defensive security reviews, including "review this Flask application for security vulnerabilities before deploying it," blocked as "violative cyber content." Five were routine bioinformatics tasks, such as running quality control on a single-cell RNA-seq file. One was a literature review on the landscape of AI-assisted drug discovery. A model from the class Anthropic markets for finding vulnerabilities in critical software declined to audit a Flask app for the developer who owns it. Anthropic's own "overly conservative" admission lands hardest here.
On the security tasks Fable did complete, it was competitive. Across 51 authentication and security skill scenarios, from Auth0, Better Auth, and Bitwarden, Fable 5 averaged 95.0 with the skill against Opus 4.8's 96.6, a near-tie. The lesson is not that one model is safe and the other is not. It is that a Mythos-class model will sometimes refuse the defensive work you most need done, and only an eval on your own tasks will tell you where.
Did Fable deliver on the Mythos promise?
Our evaluation answers the question that matters for a deployment decision: how both models handle hundreds of real, skill-driven agent tasks across dozens of tool ecosystems, which is the work most teams actually run coding agents on. The marquee Mythos feats sit outside this eval, but the day-to-day behavior it captures is exactly what you are buying when you point a fleet at a model.
What the data does show is where Fable's extra capability surfaces in normal use. Grouped by the organization that owns the skill, Fable 5 pulls ahead on web-research and scraping workloads: Apify (+7.8 overall), Google Gemini (+4.6), Tavily (+3.4), and Firecrawl (+2.7). If your agents fetch, map, and extract from the open web, Fable 5 is the stronger pick. Opus 4.8 holds its ground where Fable regresses: Mastra (-7.3), Auth0 (-4.5), and Axiom (-2.5).
So the Mythos dream of an autonomous collaborator is not what most teams will buy on day one. What they will buy is a model that is marginally better at instruction-following, meaningfully better at web research, twice the price, and gated by classifiers that occasionally hand the job to Opus 4.8 anyway.
When to use each
Choose Opus 4.8 if you run a coding-agent fleet at scale and care about cost per task. The quality difference is inside the noise for most workloads, Opus returns far more points per dollar, and it has no fallback layer to design around.
Choose Fable 5 if your agents do heavy web research and scraping, if you need its reasoning depth on long-horizon tasks, or if you have a workload that genuinely benefits from the capability class above Opus. Budget for the roughly 73% per-task premium, and build fallback detection into your harness from day one. If your work touches the classifier domains, confirm the model is not silently routing to Opus 4.8 before you depend on it.
Fable's edge shows up when you build around it, not when you swap it into an Opus 4.8 pipeline unchanged. Fable is the more autonomous model, but that edge only pays off in flows built for it: longer unsupervised runs, larger units of work, less step-by-step steering.
For almost everyone, the larger lever is neither model. The skill adds about 17 points; the model upgrade adds less than 1. Standardize the model in your tessl.json, prove the switch with an eval before you roll it to the fleet, and watch for the tasks a Mythos-class model quietly declines to do.
Want to see how a skill changes your own agent's behavior, on your own tasks, across both models? Start with the Tessl Registry and run the eval before you switch.
READING
·
0%
IN THIS POST
COPY & SHARE
YOUR NEXT READ
How Small Can an Agent Model Get? The Nemotron Floor
The article explores the minimum model capacity needed for agent models to function effectively, highlighting the Nemotron family's performance on coding tasks.


Nicolas Fortuin, Baptiste Fernandez