ARTICLE
Open-Source Agents vs Sonnet 4.6: GLM 5.2, MiniMax M3, Kimi 2.7 and Qwen 3.7 Tested
Explore the rise of open-source coding agents like GLM 5.2 and MiniMax M3. Discover how they compare to Claude Sonnet 4.6 in quality and cost.

A year ago, the choice between an open-source coding model and a frontier model from a major lab was not really a choice. You used the frontier model and paid for it. The open models were cheaper, and you could feel why.
That gap has closed. We ran four open-source models, GLM 5.2, MiniMax M3, Kimi K2.7-code, and Qwen3.7-Plus, against Claude Sonnet 4.6 through the same evaluation: nearly 1,000 real coding scenarios, each solved twice, one with no help and one with an agent skill supplying the conventions for the task. The result is not a tidy story where the expensive model wins. One open model beats Sonnet on quality and cost at the same time. Another is the cheapest thing in the test by an order of magnitude and still cannot be trusted to follow a clear instruction. The practical question is this: if you are choosing a coding agent today, how close is open-source to the frontier, and where does it still fall apart?
The setup: same tasks, with and without the skill
Every model solved the same scenarios twice. The baseline run gave the model the task and nothing else. The skill run gave it the same task plus an agent skill, the packaged conventions and instructions for the tool in question. Comparing the two runs isolates one thing: how much the model improves when you hand it the right context.
We scored each run on two axes. Instruction-following measures whether the model did the task the way it was asked, using the right APIs, conventions, and constraints. Task-completion measures whether the work runs and produces the intended result. Overall score weights them four to three in favor of instruction-following, because a coding agent that completes the wrong thing confidently is worse than one that stalls. The tasks and skills used are publicly available, in the task-evals-for-skills dataset, so you can inspect any scenario yourself.
Cost is the average dollars per task, recomputed from each scenario's measured token counts at real list prices. The four open models run on Fireworks at their published Standard rates. Sonnet 4.6 is priced at Anthropic's list. We report solve-only cost, which excludes the grading step, the same convention as the rest of the series.
One number to keep in mind: across every model, the skill adds about 20 points to the Overall score, and almost all of that gain is in instruction-following. The models could already complete most tasks. What they lacked was the conventions, and that is exactly what a skill carries.
How five coding agents score on accuracy
Here is the full scoreboard on each model's paired scenarios, baseline then with the skill.
| GLM 5.2 | MiniMax M3 | Sonnet 4.6 | Kimi K2.7-code | Qwen3.7-Plus | |
|---|---|---|---|---|---|
| Overall score | 91.9 | 91.4 | 90.8 | 88.7 | 82.2 |
| Overall score (baseline, no skill) | 71.7 | 70.5 | 66.4 | 69.2 | 62.7 |
| Overall lift from the skill | +20.2 | +20.9 | +24.4 | +19.5 | +19.5 |
| Instruction-following | 87.4 | 87.2 | 86.1 | 82.5 | 77.2 |
| Instruction-following (baseline) | 56.2 | 55.4 | 49.1 | 52.8 | 45.7 |
| Task-completion | 97.8 | 97.0 | 97.1 | 96.9 | 88.9 |
| Turns to complete | 18.5 | 22.7 | 17.7 | 27.5 | 16.5 |
| Output tokens per task | 8,813 | 8,952 | 6,841 | 21,787 | 12,296 |
| List price (input / output, per MTok) | $1.40 / $4.40 | $0.30 / $1.20 | $3 / $15 | $0.95 / $4.00 | $0.40 / $1.60 |
| Cost per task | $0.289 | $0.207 | $0.296 | $0.661 | $0.068 |
| Points per dollar | 318 | 442 | 307 | 134 | 1,204 |
Two facts jump out before any analysis. The top of the table is a near-tie on quality: four points separate first from fourth. And the cost column spans a factor of ten. The decision, in other words, is no longer about who can do the work. It is about what you are willing to pay for the last point of accuracy, and which model you can actually trust to follow instructions.
Line the five models up by cost and by quality and three of them earn their price: Qwen at the cheap end, MiniMax in the middle, and GLM 5.2 at the top. Nothing in the test beats any of these three on both cost and quality at once. Sonnet 4.6 is not one of them. GLM 5.2 scores as high and costs slightly less per task, so on this test there is no reason to reach for Sonnet over it. Kimi is the most expensive model in the test and only the fourth most accurate.
The model that ties Sonnet
The headline of this series promised an open model that ties Sonnet. The data is stronger than that. GLM 5.2 finishes at 91.9 Overall against Sonnet's 90.8, and it does so at $0.289 per task against Sonnet's $0.296. When directly comparing the scenarios that all five models ran, GLM 5.2 reaches 93.5 and Sonnet 91.9. The open model is ahead on quality and on cost.
There is a nuance worth stating precisely, because it cuts the other way and the comparison should be fair. On those tasks, Sonnet is the single best model on 54 percent of them, more than any other model. So Sonnet wins the typical scenario by a small margin. GLM 5.2 still comes out ahead on the average because it is more consistent: it has fewer catastrophic low scores dragging its mean down. If you care about the median task, Sonnet edges it. If you care about avoiding the bad day, GLM 5.2 wins. Both readings are true, and both point at a real tie at the top rather than a blowout.
MiniMax M3 lands in almost the same place as Sonnet on quality, 91.4 to 90.8, while costing about 30 percent less per task. It is the value pick at the top of the table.
The model that won't listen
Qwen3.7-Plus is the cautionary tale, and the interesting thing is how it fails. It is not simply a weaker model that scores lower everywhere. It is a model that will do the work and ignore your instructions while doing it.
Start with the obvious signal. Qwen has the lowest instruction-following score in the test, 77.2 with the skill against 82 or higher for everyone else, and the lowest baseline at 45.7. But the average understates the problem, because Qwen's scores are volatile. Sixteen percent of its scenarios still score under 50 on instruction-following even with the skill in hand, compared to 6 to 13 percent for the rest. The skill is right there and it gets ignored one time in six.
The clearest evidence is in task-completion. Every other model sits at 97. Qwen sits at 88.9, the only model whose ability to finish the job also sags. When we look at the scenarios where Qwen scores low on instruction-following, most are not cases of it giving up. In 116 of them Qwen completed the task to a high standard but followed the instructions poorly, against 87 where it failed both. That 116 is the whole thesis in one number. Handed the conventions for a tool, Qwen frequently builds something that works, in its own way, ignoring how it was asked to build it.
Adding the skill can even backfire. For most models the skill almost never hurts; 3 to 6 percent of scenarios regress. For Qwen, 14 percent regress, with some catastrophic single drops. A scenario that scored 100 at baseline fell to 4.6 with the skill. Two others fell from 88.6 to zero. The skill does not just fail to help Qwen on these tasks. It actively derails the model, which then spends 38 percent more turns and 28 percent more money to arrive at a worse answer. If you are running an agent loop unattended, that combination of cheap, confident, and non-compliant is the worst profile in the table.
Where every agent stumbles: web research and scraping
The most useful finding is not about any one model. It is the cluster where all five break the same way: web research and scraping. Group those skills together, Firecrawl, Tavily, Apify, Browser-use, Brave, Exa, and LangChain, and every model's instruction-following collapses relative to its own work elsewhere. GLM drops 20 points, Kimi 27, Qwen 15, MiniMax 13, and Sonnet 18. The hardest scenarios in the entire test, by mean score across all five models, are dominated by Firecrawl command-line tasks and a Cloudflare investigation-notes scenario that averages 18.9 out of 100.
It is also where models most often step outside their sandbox, reading files they were not given, scanning the filesystem for API keys, or hunting for the grading criteria instead of solving the task as set. These out-of-bounds flags hit 16 to 36 percent of cluster scenarios against single digits elsewhere, with Sonnet the worst at 36 percent. The pattern fits the task: scraping and search skills need API credentials, so the models go hunting for keys rather than working only from what the task provided.
The honest takeaway is that web research and scraping are simply hard for every model, open or closed, and Sonnet stumbles here exactly like the open ones. These tasks involve live network calls, long agentic loops, and grading checks that are easy to satisfy superficially. If you deploy any of these agents on scraping or research workloads, expect a 15 to 25 point drop from your clean-task instruction-following, and budget for the occasional run that costs an order of magnitude more than the median. And spending more does not help: output tokens and turn count both correlate slightly negatively with the Overall score, so the long, expensive runs are the ones thrashing toward a wrong answer, not doing careful extra work.
Which coding agent should you pick?
The skill is the great equalizer, so the first rule is to use one. It adds about 20 points to every model, and it adds the most, 24.4, to Sonnet, which starts mid-pack at baseline and only reaches the top tier once it has the conventions. Without the skill the ranking reshuffles entirely. The model you would pick depends almost entirely on whether you give it the right context, which is the whole premise of treating skills as first-class software.
With that settled, here is the opinionated guidance.
Choose GLM 5.2 if you want the highest accuracy and you are not paying frontier-lab prices to get it. It tops the table, it is the most consistent model in the test, and it costs less per task than Sonnet. For most teams comparing against a Claude or GPT default, this is the result that should change your spend.
Choose MiniMax M3 if you want Sonnet-level quality at the lowest cost among the strong models. It matches Sonnet within a point at about 30 percent less per task.
Choose Sonnet 4.6 if you are already in the Anthropic ecosystem and value the per-scenario edge on typical tasks. It wins the most head-to-head matchups, refused nothing in our run, and is the leanest model on output tokens. You are paying a small premium for that consistency-versus-peak tradeoff, and on this test an open model matches it.
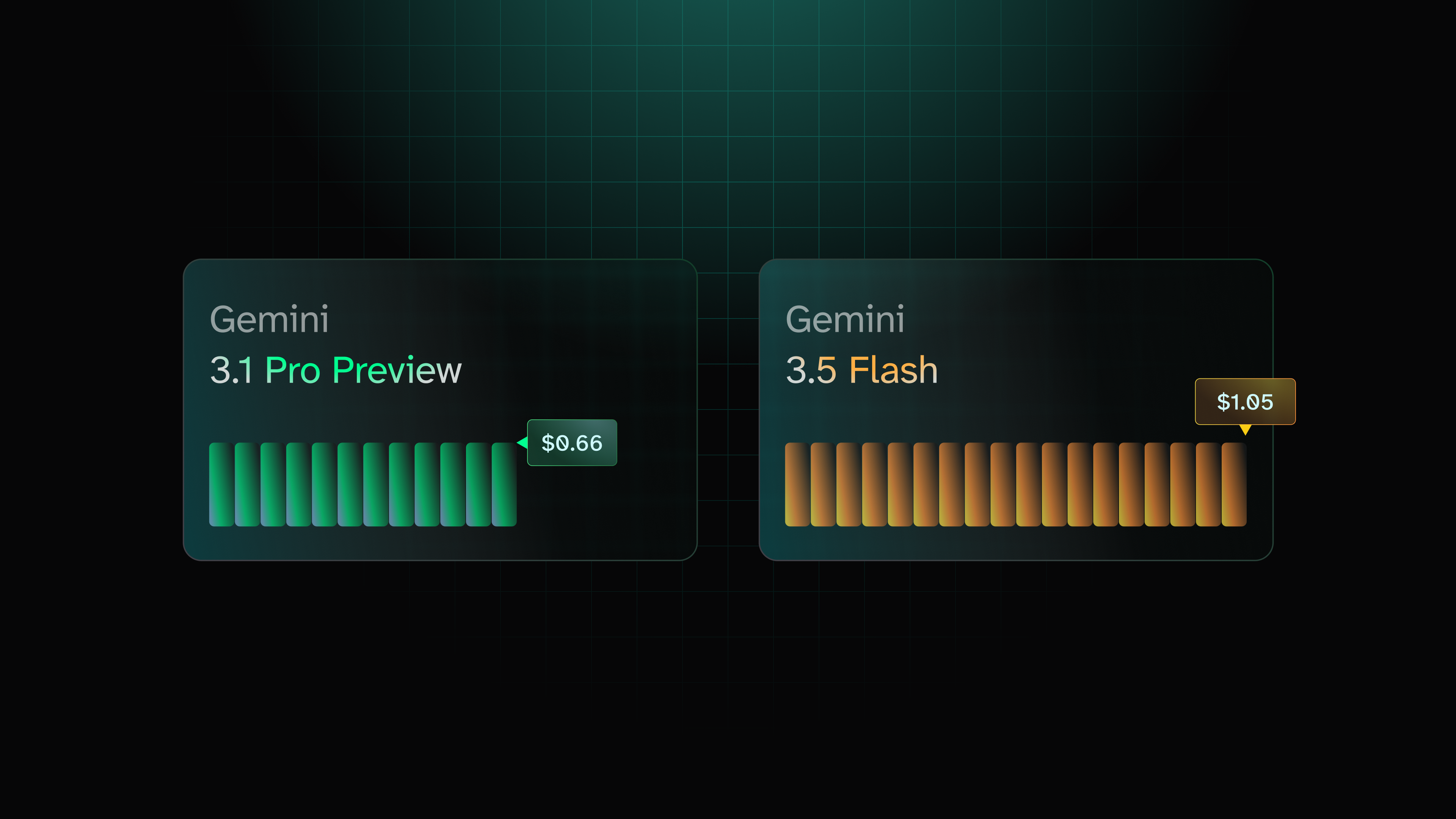
Reach for Kimi K2.7-code on focused coding tasks where completion matters more than cost. Kimi finishes the job as reliably as the leaders (96.9 task-completion); its weaker spot is following instructions to the letter. Per token it is cheaper than GLM and Sonnet, so on short-output work it costs less than its $0.66 average suggests, but it tends to run long, which makes it better suited to high-value, lower-volume work than to large fleets.
Treat Qwen3.7-Plus as a specialist, not a generalist. At $0.068 per task it is cheaper than everything else by a wide margin. But it follows instructions worst and its quality is the most volatile. Use it where the task is forgiving and the savings dominate. Do not use it where doing the task the prescribed way actually matters.
The broader signal is the one the pricing pages miss. Open-source coding agents have caught the frontier on accuracy, and the gap that remains is not capability but reliability. The same skill carried every model up by about the same amount, which means the differentiator is no longer raw model quality. It is whether the model listens.
READING
·
0%
IN THIS POST
COPY & SHARE
YOUR NEXT READ
How Small Can an Agent Model Get? The Nemotron Floor
The article explores the minimum model capacity needed for agent models to function effectively, highlighting the Nemotron family's performance on coding tasks.


Nicolas Fortuin, Baptiste Fernandez