ARTICLE
Why Your Gemini Bill Doesn't Match the Model Names
Discover why your Gemini bill doesn't align with model names. Explore cost discrepancies and performance insights. Uncover the real story now!
Why Your Gemini Bill Doesn't Match the Model Names
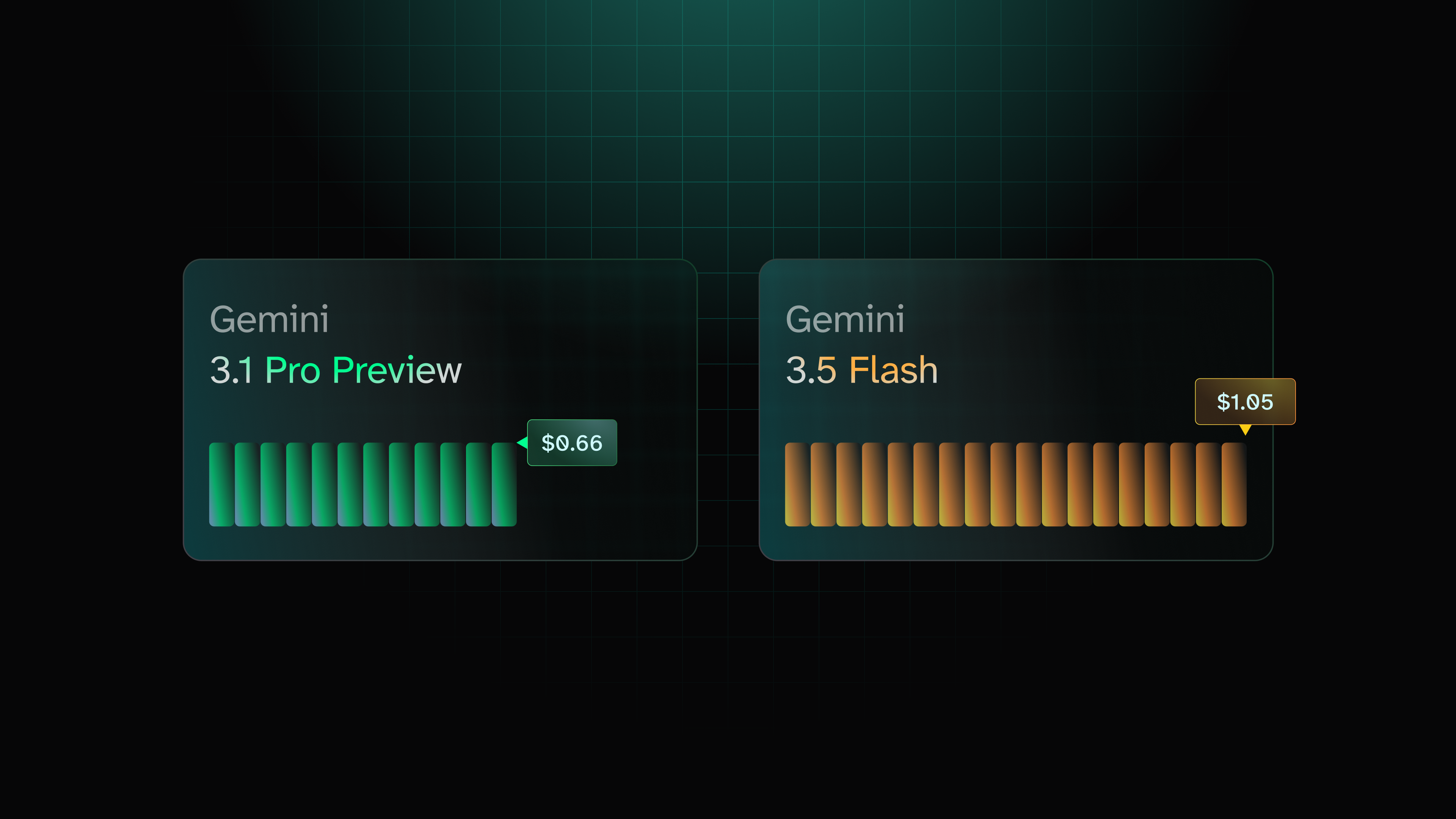
tl;dr - Across roughly 3,300 paired skill-eval runs, Gemini 3.5 Flash cost $1.05 per task against Gemini 3.1 Pro's $0.66, for scores that were effectively identical: 88.6 versus 87.9.
The pricing is even stranger when you look at the actual task costs. Gemini 3.5 Flash and Gemini 4.5 Flash are separated by almost 8× in per-task cost, while Gemini 3.1 Pro comes in cheaper than both. The invoice does not appear to follow the naming hierarchy.
Where the numbers come from?
The benchmark ran every task twice, once with the relevant skill applied and once without, across four Gemini models in OpenHands, totaling roughly 800 tasks per model. Rather than relying on dashboard estimates, we pulled per-call token counts directly from agent session logs and computed costs using Google's published per-token prices. We then compared the resulting per-task costs across models.
The headline data
| Model | $/task (w/ skill) | Score | Pts per $ | Input tokens | Turns | List $/Mtok |
|---|---|---|---|---|---|---|
| 3.1 Flash Lite | $0.035 | 70.2 | 2,006 | 0.31M | 17 | $0.25 |
| 3 Flash Preview | $0.135 | 85.4 | 633 | 0.63M | 24 | $0.50 |
| 3.1 Pro Preview | $0.66 | 87.9 | 132 | 0.65M | 26 | $2.00 |
| 3.5 Flash | $1.05 | 88.6 | 85 | 1.41M | 39 | $1.50 |
A few things stand out from this data.
- Cost order and name order are uncorrelated. Gemini 3.1 Pro is cheaper per task than Gemini 3.5 Flash despite carrying a higher per-token list price, while Gemini 4.5 Flash and Gemini 4.5 Flash-Lite, which sit in the same product family, differ dramatically in actual spend. Model names describe intended positioning, but they are a poor guide to real-world agent costs.
- Scores do improve with each model generation, which is a genuine positive trend and a good reason to track releases, but capability gains do not automatically translate to cost reductions.
- Finally, the practical value pick is Gemini 3 Flash Preview, which lands within three points of the leading models at roughly one-fifth the per-task cost, making it the most efficient option for workloads where a score in the 85 range is acceptable.
Why volume beats unit price
The cost of an agentic task is the product of two variables:
Task cost = price-per-token × tokens the model decides to spendModel names establish the first variable. The second is determined at runtime by the model's behavior on the specific task, and it only becomes visible after you read your session logs.
For Gemini 3.5 Flash, the per-task cost breaks down as follows:
- Non-cached input:
$0.72 - Cache-read input:
$0.14 - Output (including thinking):
$0.19
The dominant driver is input volume. Gemini 3.5 Flash sent 1.41 million tokens of context across 39 agent turns per task. Pro sent roughly half that volume across 26 turns, and even at its higher list price of $2.00 per million tokens, its lower volume resolves to a lower total bill.
A model with a cheaper per-token rate that takes more turns to reach an answer will erode its own discount. It is also worth noting that 63-75% of input across these runs was cache-read, which means the effective sensitivity to turn count is even higher than raw list prices suggest: the multiplier is accumulating in your session logs, not on your pricing page.
Skills move cost by tier
Adding a relevant skill to each run changed per-task cost in opposite directions depending on which model ran it:
- Pro saw cost drop $0.20 per task (-23%) while the score gained 20 points. The model used fewer turns and less exploratory backtracking, which suggests it was able to act on the structured guidance directly rather than discovering the solution path through iteration.
- 3.5 Flash was essentially flat, with cost shifting by less than $0.03 in either direction.
- 3 Flash Preview and Flash Lite each spent slightly more tokens for marginal score gains (+$0.03 and +$0.01 respectively).
The underlying pattern is consistent: a skill compresses the solution path for a model capable of following structured guidance precisely, reducing turn count and therefore total cost. For a model still resolving ambiguity through exploration, the same skill adds context to process rather than a shortcut to apply, and the cost holds steady or rises marginally. A skill is a shortcut for a capable model and overhead for a weaker one.
In practical terms, this produces two clear operating points. Pro with a relevant skill at $0.66 per task is the most cost-efficient route to top-tier performance. Gemini 3 Flash Preview with a skill at $0.135 per task delivers roughly five times the score-per-dollar of either leader, for a score three points lower, which is a reasonable trade for many workloads.
Measure, don't assume
Four takeaways from this data that apply beyond this specific benchmark:
1/ Do not budget from the rate card. Cost your workload based on measured tokens and turns on your specific tasks, with your specific prompts, in your specific agent harness. Per-token list prices are a useful first filter for ordering candidates, not a reliable predictor of relative spend.
2/ Read cost at the session layer. Aggregate dashboards can show $0 while spend accumulates in the background. Token usage needs to come from raw API responses or agent session logs to be trusted for budgeting purposes.
3/ Watch turn count first. The 39-versus-26 turn gap between 3.5 Flash and Pro is the primary cause of the price inversion observed here, and turn count is the variable most commonly absent from observability tooling. It is the multiplier on everything else in the cost equation.
4/ Re-measure when models update. Gemini 3.5 Flash is a newer release than Gemini 3 Flash Preview and scores higher, but it costs roughly eight times more in this agentic context. Capability improvements and cost improvements are independent variables, and any cost benchmark needs to be re-run with each version update rather than assumed to hold.
Caveats
These results come from a single agent harness (OpenHands), a single benchmark with explicit skill-relevance disclosure, and a specific sample window. Different tasks, prompt structures, and turn-length patterns will shift the absolute numbers and may shift the relative rankings. The finding to carry forward is not a specific model recommendation but a methodology: in agentic settings, cost rankings are not derivable from per-token rates alone, and the ranking that applies to your workload depends on that workload's specific behavioral profile.
A model name is a pricing tier, not a cost forecast. In agentic workflows, the deciding variable is how many tokens the model chooses to spend to reach an answer, a figure visible only after you run the work and read the logs. The rate card gives you one of the two inputs; only measurement gives you both.
Next: which skills actually earn their tokens? In these runs, 42% produced significant performance gains while 5% were net overhead. We’ll follow up on this analysis in the next post.
COPY & SHARE

Rob Willoughby
Rob Willoughby is AI Research Lead at Tessl, where he leads the team building Tessl’s evaluation framework. He works at the intersection of applied AI research and product, focused on the question of how you actually know whether an agent is doing what you think it is. He’s previously worked on AIML systems across Apple, Twitter and Google DeepMind.

Baptiste Fernandez
Building AI Native Development community, spotlighting exciting releases and innovations in the space
READING
·
0%
IN THIS POST
COPY & SHARE
Rob Willoughby
Rob Willoughby is AI Research Lead at Tessl, where he leads the team building Tessl’s evaluation framework. He works at the intersection of applied AI research and product, focused on the question of how you actually know whether an agent is doing what you think it is. He’s previously worked on AIML systems across Apple, Twitter and Google DeepMind.
Baptiste Fernandez
Building AI Native Development community, spotlighting exciting releases and innovations in the space
YOUR NEXT READ
How Small Can an Agent Model Get? The Nemotron Floor
The article explores the minimum model capacity needed for agent models to function effectively, highlighting the Nemotron family's performance on coding tasks.

Nicolas Fortuin, Baptiste Fernandez